

Nicola Romanò @nicolaromano@qoto.org
- Pronouns
- he/him
Senior lecturer at Edinburgh University and Zhejiang-Edinburgh Joint Institute (ZJE).
Undergraduate Programme Organiser, Biomedical Informatics at ZJE.
I teach #imageanalysis & #dataanalysis with #RStats & #python.
My research is focused on how #heterogeneous behaviour in #pituitary (and other) cells shapes their function as a population.
I'm also very interested in #reproducibility and #openscience.
Joined Oct 2022
Nicola Romanò
boosted

How a misinterpretation of a BMJ publication from 1996 caused (and yes, I do mean caused) the explosion in rates of peanut allergy.
In a nutshell: for decades the guidance issued in the USA and UK was the opposite of what it should have been and left a generation with preventable, life-threatening allergies.
https://news.harvard.edu/gazette/story/2024/10/excerpt-from-blind-spots-by-marty-makary/
Nicola Romanò
boosted

@pyconasia @mariatta
I was told that being a woman is just being a bride.
But I was rebellious and I went to study.
Nicola Romanò
boosted

A question about data management during (bioinformatics) analysis:
do you use any of:
- git annex
- DataLad
- something else? (git LFS...)
Why?
I see several hurdles with directly using git-annex, such as the need to unlock files before modifying them (useful for raw data, inconvenient for intermediate data).
Nicola Romanò
boosted

Which scientific publishers/journals are worst affected by fraudulent or dubious research papers, and which have done least to clean up their portfolio?
A science-integrity startup called Argos says it has answers.
There are quite a few integrity tools now that look for red flags in papers, but this is the first to go public with what it's finding across journals and publishers.
Here's my exclusive look at their figures.
https://www.nature.com/articles/d41586-024-03427-w
Nicola Romanò
boosted

“tinytable is a small but powerful R package to draw beautiful tables in a variety of formats: HTML, LaTeX, Word, PDF, PNG, Markdown, and Typst. The user interface is minimalist and easy to learn, while giving users access to powerful frameworks to create endlessly customizable tables.” - @vincentab
Nicola Romanò
boosted

[New paper]: Two subtle problems with over-representation analysis.
ORA is a type of enrichment analysis that analyses over-represented functional categories in gene lists. These tools have accumulated ~190k citations, but they have subtly different behaviours. Here we unpack the differences and investigate two subtle problems in some implementations, which may have negatively impacted those 190k research papers.
https://doi.org/10.1093/bioadv/vbae159
#genomics #bioinformatics
Nicola Romanò
boosted

I’m a software developer with a bunch of industry experience. I’m also a comp sci professor, and whenever a CS alum working in industry comes to talk to the students, I always like to ask, “What do you wish you’d taken more of in college?”
Almost without exception, they answer, “Writing.”
One of them said, “I do more writing at Google now than I did when I was in college.”
I am therefore begging, begging you to listen to @stephstephking: https://mstdn.social/@stephstephking/113336270193370876
I've created a little schematic on basic Git/GitHub usage.
Feel free to reuse! (CC-BY-NC-4.0)
Nicola Romanò
boosted

Six tips for going public with your lab’s software: https://www.nature.com/articles/d41586-024-03344-y
1) make time for maintenance
2) simplify installation
3) add a GUI or good CLI
4) good documentation
5) use github/git
6) automated testing
Any other tips people have? #SoftwareEngineering #opensource #openscience
Nicola Romanò
boosted

@computingnature
These cover a lot of common problems I have with scientific code, one minor one to add is "build more, smaller things" - splitting up a very large monolithic code base into several smaller pieces can work with all the above tips to make the software much more useful over time. Being able to re-use pieces between projects without needing to make future projects direct dependents of humongous prior packages is a huge deal for labs that might make many tools.
Nicola Romanò
boosted

#academicchatter I read a published paper on the other day and noticed a panel in the figure is clearly duplicated but by mistake, I knew this because the authors uploaded the raw data as table and the table has a complete set of numbers that doesn't match the figure panel. Importantly the correct data didnot change the conclusion. This
#openscience approach either enforced by publishers or volunteered by authors maintained the trust I have with the finding they reported.
Nicola Romanò
boosted

"My paper was proved wrong. After a sleepless night, here’s what I did next"
column by @oaggimenez describing how to gracefully react when mistakes are discovered in ones published papers.
Nicola Romanò
boosted

@zaunkoenig @jonny sorry, but, if you are talking about scientific research, it's absolutely not true that any complex model uses NNs nowadays. You can verify this yourself by checking out any reputable scientific journal, for example those of the APS (the Physical Review ones).
Nicola Romanò
boosted

Nicola Romanò
boosted

to celebrate selling out the first print run of How Integers and Floats work, we're giving away 500 PDF copies of the zine!
use code BUYONEGIVEONE at checkout to get a copy for free. (no need to enter your real address)
As usual this works with the honour system, this code is for you if $12 USD is a lot of money for you!
Nicola Romanò
boosted

Wow it transports 20 people. ooooh I have an idea, what if we connected a bunch of these together... in a long chain and put them on tracks to make them more energy efficient (and to meet power needs) then ran them along the most popular transportation corridors in major cities! They could even go in tunnels in places like NYC to reduce traffic!
Golly Elon is on to something this time!
Nicola Romanò
boosted

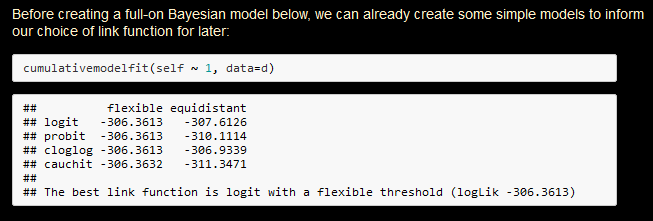
#statstab #198 Bayesian mixed effects (aka multi-level) ordinal regression models with {brms}
Thoughts: Useful tutorial also for frequentists, as it covers checking multiple links at once in {ordinal}.
#ordinal #brms #clmm #probit #cloglog #r #cauchit
https://kevinstadler.github.io/notes/bayesian-ordinal-regression-with-random-effects-using-brms/
Nicola Romanò
boosted

What a massive, cool project. Such huge many lab collaborations are becoming more and more common and I am HERE for it.
Nicola Romanò
boosted

@jeffowski #AI is an academic field of endeavour first. Just because there is some grifting and questionable actors now does not mean you can write it and all people involved in it off like that.
That is like saying Physics is a scam because people were pedding perpetuum mobila, writing of medicine because people are peddling miracle cures or writing off Computer Science because of the dot-com boom.
Nicola Romanò
boosted

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
I find it concerning and unsurprising that The Nobel Prize team called out their own sexism, likely without realising it:
"This morning [the Nobel laureate] celebrated the news of his prize with his colleague and wife Rosalind Lee, who was also the first author on the 1993 'Cell' paper cited by the Nobel Committee."
- Pronouns
- he/him
Senior lecturer at Edinburgh University and Zhejiang-Edinburgh Joint Institute (ZJE).
Undergraduate Programme Organiser, Biomedical Informatics at ZJE.
I teach #imageanalysis & #dataanalysis with #RStats & #python.
My research is focused on how #heterogeneous behaviour in #pituitary (and other) cells shapes their function as a population.
I'm also very interested in #reproducibility and #openscience.
Joined Oct 2022
