

Paweł Lenartowicz @plenartowicz@qoto.org
- Profile in Polish:
- @plenartowicz@lewacki.space
Aspiring statistician and meta-researcher, sailor and activists.
#PhilosophyofScience
#OpenScience
#Uncertanity
Joined Nov 2022
I'm quite sure that I agree with you. But, in my opinion, it's problem with lack of rigour and putting too much confidence in "statistical ritual" than p-value itself. Let me provide some example:
1) We are using p-value to detect candidate genes in some traits, like depression, anxiety, intelligence...
2) We can conduct some meta-analysis of such analysis, to make sure that candidate gene has effect, and obtain some "satisfying low p-value", like p = .00002 (σ > 4) and based on these results to conclude that we have strong evidence for effect.
Point "2)" is wrong, and there is a little evidence in it, but I think, that using p-value to detect "candidates" is defendable. Or, at least, I'm not aware of any better method.
Fisherian aproach was intoduced in 1925, while Jerzy Neyman proposed his solution in 1926.
It's amazing that after almost 100 years, there are lively discussions about them!
In my opinion, these are two different, not always competitive tools, like screws and nails.
If we have specified hypothesis to test, it'll be better to use Neyman approach and calculate LR or other suitable test, with satisfying α and β.
But, when we want to just test null hypothesis for error detection, or basic exploratory analysis, p-value seems to be good approach.
@david_colquhoun @raoulvanoosten @lakens
Except Schrodinger's cat ;)
Paweł Lenartowicz
boosted

I guess maybe don't use references chatGPT throws at you not because they can be wrong or fake but because, idk, you haven't actually read them?? If people first read & understand stuff they wanna cite, like one does, perhaps it wouldn't matter how they got to those references.It's weird to be scandalized by the possibility of a model making up references while normalizing scientists' lack of basic scientific integrity. I know which one is more horrifying to me.
@OskarA
It's amazing that such ignorant and genocide denier as Chomsky is still considered an expert.
You can scatterplot everything, but that doesn't mean it makes sense. Especially plotting ranked data doesn't. In the best scenario, it's waste of time, for both authors and readers.
Also, linear regression is the wrong method to analyze such data. None of the assumptions were met!
But, IMO, the problem is field-wide: correlation study instead of an experiment, no data analysis plan at preregistration, no power analysis, non-random sample, no clear relation between theory and operationalization, big potential for p-hacking and so on...
@ct_bergstrom
"Evolutionary psychology" is largely a pseudscience.
@uebernerd
It's clearly statistics with p-value:
1:1 => p=0.3173105188
2:1 => p=0.0455001240
3:1 => p=0.0026999344
4:1 => p=0.0000633721
5:1 => p=0.0000005742
But the problem is elsewhere. In experimental social science "effect size" and "sampling error" are artifacts of method, when data rarely meet the assumptions.
Triangulation is IMHO better idea than efforts to lower p-values: https://www.nature.com/articles/d41586-018-01023-3
Paweł Lenartowicz
boosted

@atomicpoet @martinvermeer
Maybe, you would like something like graphene OS or LineageOS, which are non-google Android distros.
There is plenty of alternative OS. And plenty of Android distribution too: https://en.wikipedia.org/wiki/List_of_custom_Android_distributions
Paweł Lenartowicz
boosted

Non-profit journals as a solution to open science?
Publishers charge researchers incredible amounts to remove paywalls from their own papers...and make unbelievable profits from doing so. Several have an >30% profit margin.
Initiatives such as @PeerCommunityIn provide an alternative: open access, non-profit journals that are free to publish in.
https://peercommunityin.org/
https://peercommunityjournal.org/
#OpenScience #Science #AcademicChatter @academicchatter
Graph (2013): @alexh https://alexholcombe.wordpress.com/2013/01/09/scholarly-publishers-and-their-high-profits/
@mgaruccio @atomicpoet
Also, isn't Apple using Darwin, which is UNIX(like) Kernel?
@lakens
What a beautiful ergodic distribution <3
Paweł Lenartowicz
boosted

I have a doctorate in Artificial Intelligence and I just needed 7(!) tries to spell the word "Artificial" correctly. I guess I'm more tired than I'm willing to admit to myself.
#PostDocLife #Deadline #ArtificialIntelligence #tired #AcademicMastodon #AcademicChatter
@uebernerd
Yes, but:
1) there should be some robust system for identifying and archiving articles (in case of a blog-site shutdown, or similar);
2) In my opinion, the peer-review system is ineffective and biased, however, I think that without it, process would be much more (status) biased and vulnerable to fraud, corruption, conflict of interests and so on.
Paweł Lenartowicz
boosted

👉 Do you want to become a better researcher?
👉 Do you feel insecure about making your work more open?
Sign up to join us for a month full of
✅ reflections on your career,
✅ discussions about the way we practice science, and
✅ practical steps towards #OpenScience
12 emails 💌 over the course of a month that are designed to help you on your Open Science journey.
Paweł Lenartowicz
boosted

![]() Hello and a good meowing everyone!
Hello and a good meowing everyone! ![]() Have a most wonderful day and have fun
Have a most wonderful day and have fun ![]() ❤️
❤️ ![]()
@breadandcircuses @Caitoz
I'm disgusted with the manipulation of the authors of this graph.
They are comparing the mean to the median, of, even not every worker, but some part of them, "traditional blue collars"
which decrease since 70'...
More than half of this "disconnection" is clearly a lie, the second part is about growing inequality. Which is catastrophically bad, but we do not have to lie to show or prove that.
Paweł Lenartowicz
boosted

#PsychologicalScience (the journal) after the replication crisis.
A z-curve analysis
https://replicationindex.com/2022/10/20/princeton-talk-about-z-curve/
The % of significant (p < .05, z > 2) results has not changed much (ODR = 75% vs. 71). However, the actual power to get these results has increased a lot (EDR = 21% vs. 68%). As a result, the false discovery risk has decreased from 20% to 2%.
Look out for the 2023 replicability rankings coming soon.
https://replicationindex.com/2022/01/26/rr21/
- Profile in Polish:
- @plenartowicz@lewacki.space
Aspiring statistician and meta-researcher, sailor and activists.
#PhilosophyofScience
#OpenScience
#Uncertanity
Joined Nov 2022
Paweł Lenartowicz's choices:

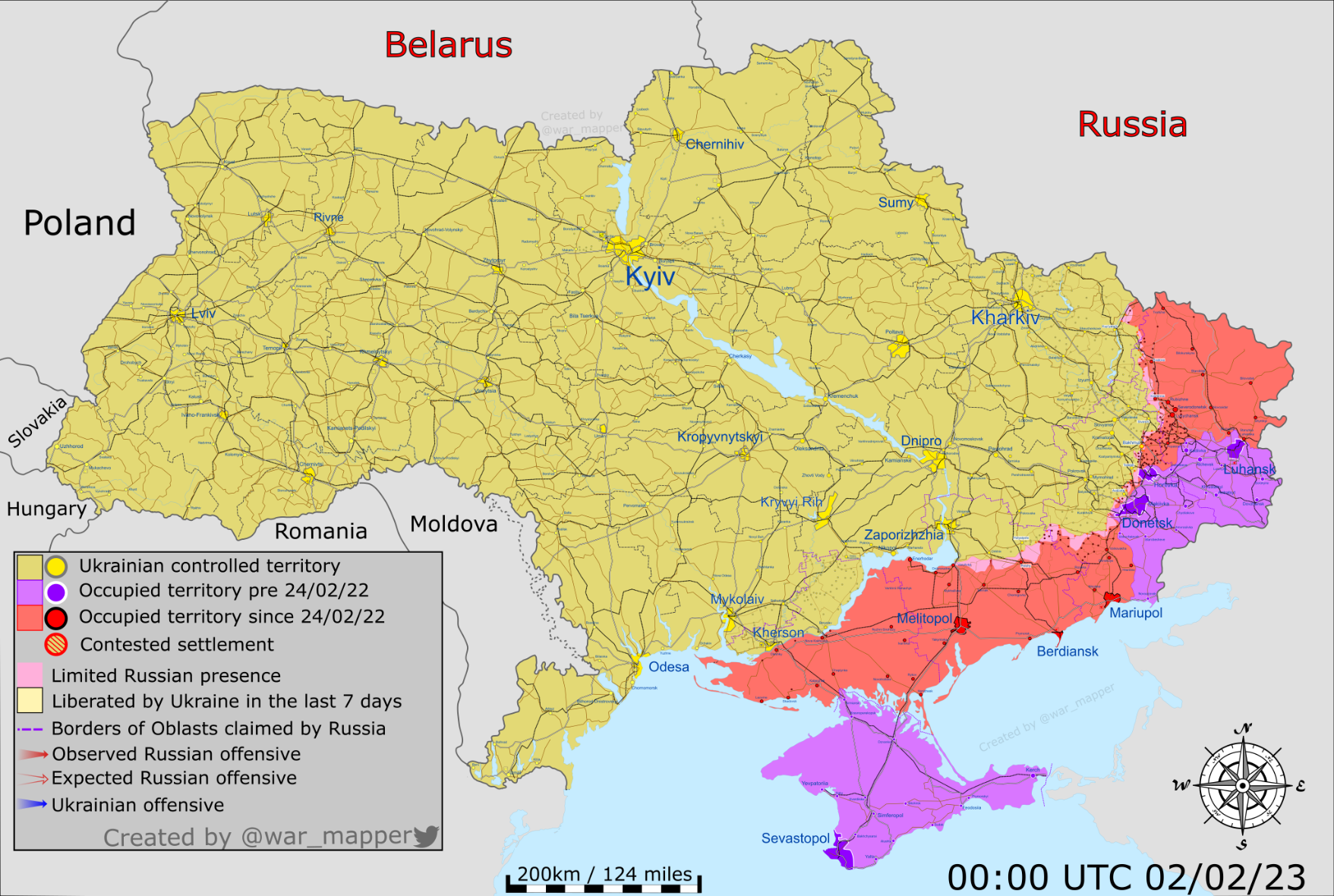{kind=link}
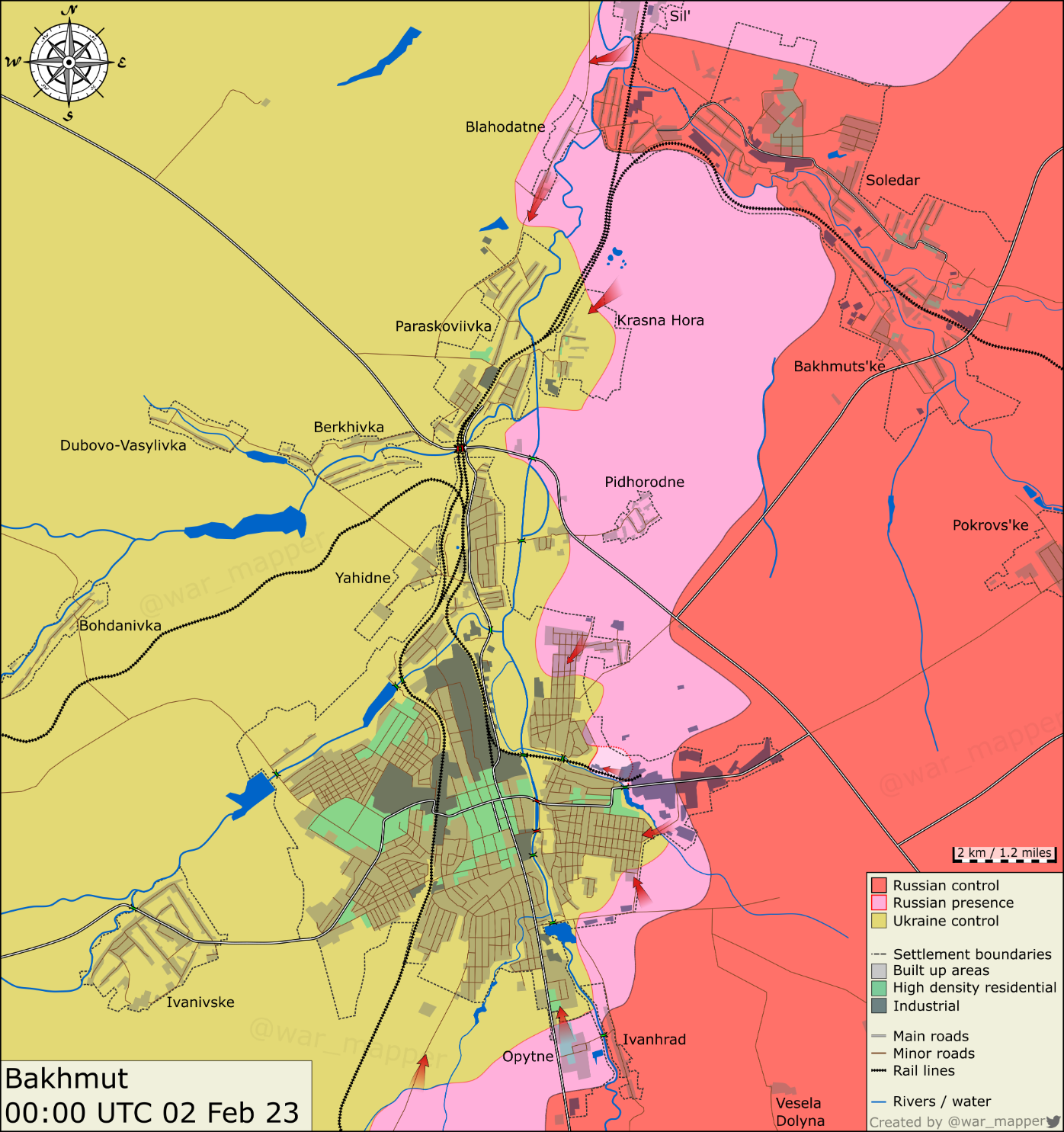{kind=link}
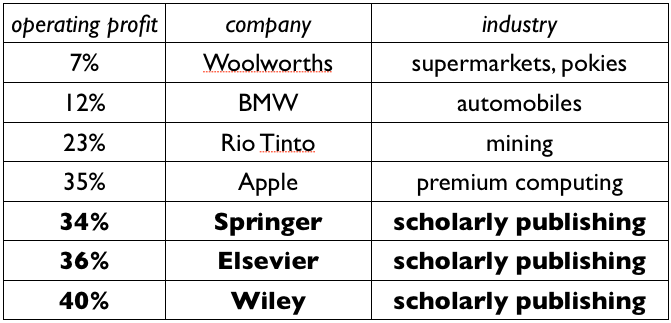{kind=link}
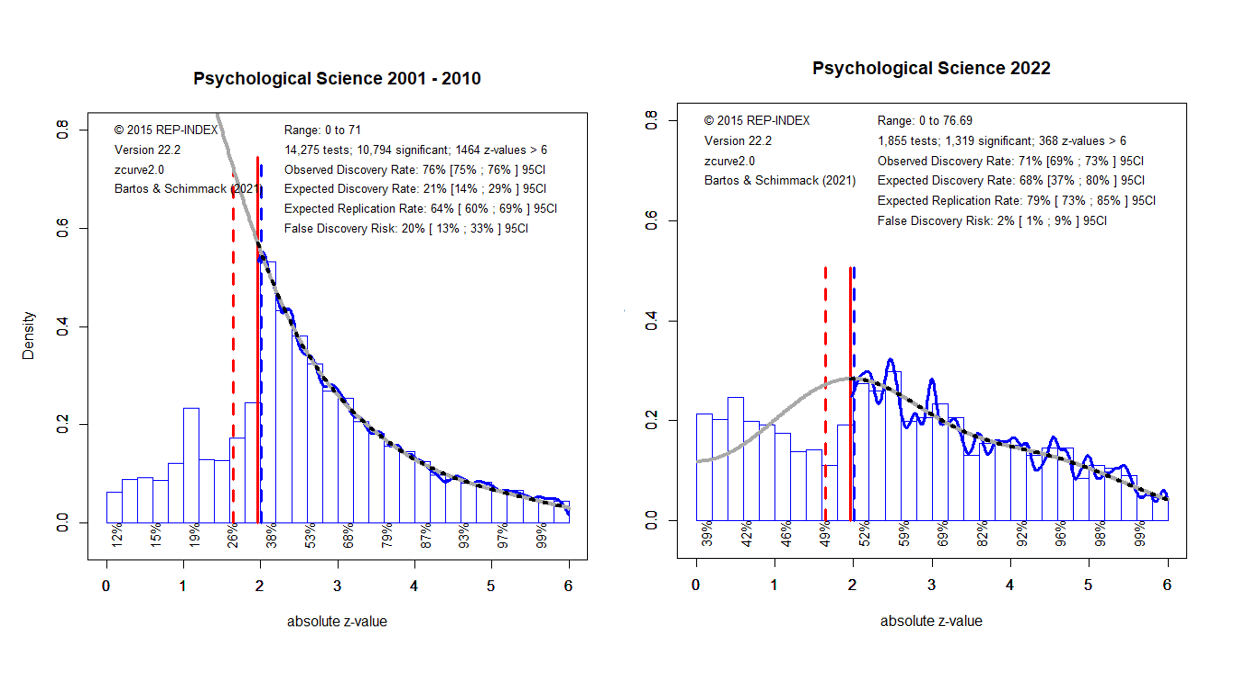{kind=link}
