

V_Iacovella @v_iacovella@qoto.org
full stack technician working on #openaccess and #opendata at CIMeC - Center For Mind / Brain Sciences at The University of Trento (Italy)
founder and steering committee of the Italian Reproducibility Network
Bolzano is just 60 km from Trento but every time I come here it feels Iike traveling 10 years in the future. This is my first time at #sfscon and I am sure I will get a taste of the shape of technology to come.
Chi acquisisce dati per scopi scientifici e si prepara alla condivisione deve sentirsi parte di un processo di riuso responsabile delle informazioni.
Ho preso alcuni appunti a riguardo che discuterò oggi pomeriggio al convegno "La comunità prima della commercializzazione" all'Università di Trento.
Condividere informazioni significa automaticamente esporle al riutilizzo. Per facilitare questa operazione occorre calibrare ciò che si condivide posizionando il contributo in un'area che copra insieme rilevanza scientifica e riuso responsabile. Questo è possibile ricorrendo a schemi standard e #FAIR che garantiscono l'interoperabilità delle informazioni.
Per parafrasare un'espressione ormai celebre nell'ambito dell'#openscience, partecipare come parte della comunità al processo di costruizione del sapere tramite la condivisione dei dati vuol dire condividerli "as structured as possible, as derived as necessary.".
In this same room I defended my PhD exactly 10 years ago. It was nice to come back and present at #AISC2022 one of the initiatives I care about the most: the @italianrepro
Single researchers or small teams are proving increasingly inadequate to address current scientific challenges.
That is why we at @italianrepro asked Nicholas Coles, director of the [Psychological Science Accelerator](https://psysciacc.org/) – recently awarded by the Einstein Foundation - to talk about “Multi-lab and Multi-site Projects; the Psychological Science Accelerator” in the [2nd Online Seminar on Open Science for year 2022/23](https://www.itrn.org/initiatives/onlineseminars).
Seminar is completely online, tomorrow Wednesday December 14th at 5pm CET.
[Participation is free and open to everyone interested](https://www.itrn.org/initiatives/onlineseminars) in #openscience and #multilab / #multisite collaboration projects.
[Book a virtual place for the zoom room!](https://www.itrn.org/initiatives/onlineseminars)
@NehaKhazanchi on the image you posted, lists are the fifth button from the left, the "bullet list" one.
When you click on a profile you can choose to add it in a list. You can visualize a list timeline showing only toots from people within that list.
On twitter people used to build and maintain lists of accounts talking about specific topics to have a sort of automatic "digest" of what's going on in that field.
I am still trying to figure out whether lists are public. I am pretty sure that you cannot follow other people's lists. I guess it could be of interest at least to browse them. For example, here is the link to my "open knowledge" list -> https://qoto.org/web/timelines/list/1829

Proudly sharing our new steering committee from February 2023. Meet new members Dario Mangione, Ezia Rizzi & Claudia Mazzuca.
We are excited for the new year and for the impactful work to come!
w/ @CarloMiniussi @massimo006 @v_iacovella @zogmaister @timetit & Davide Crepaldi
IMVHO the actual #inboxzero goal should be to empty out the draft directory
@fewohlgemuth you could check [gin.g-node](https://gin.g-node.org/) and if it works for your purposes you may consider [deploying the service on your own machines](https://gin.g-node.org/G-Node/Info/wiki/In+House) for internal use. It is thought to be used for neurosciences but there is no specific cut shaping up the way in which you should organize your data, so I guess it may work basically in every context.
@HeidiSeibold not related to mistakes, but to avoid them: a couple years ago there was published [an interesting guide](https://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1007358) mainly related to pipelines to analyze neuroimaging data. However, I think the general concepts apply to many other fields.
@OpenScienceFeed thanks for your comment.
I would agree with the second part (resources, skills, etc), even if I would say that you can keep it just informal / conversational and still dig out something from it. I would say that doing well on social media for scientific purposes have a different meaning wrt to the "standard" one (many followers, consistent interactions, etc).
Regarding the first part: I meant that it might be more likely to discuss with "big names" of a field online, where content - based conversations are basically open to everyone and in an asynchronous way, with respect to - for example - physical tables with restricted access in in - person conferences.
This thread could also work as my official #introduction here after switching servers.
I work as full-stack technician for [Think Open](https://www.cimec.unitn.it/en/1025/open-science), the #openscience initiative of [CIMeC - Center For Mind / Brain Sciences](https://www.cimec.unitn.it/) at [The University of Trento, Italy](https://www.unitn.it/).
I also contributed to establish and maintain the [Italian Reproducibility Network](itrn.org) @italianrepro
My main activity is to discover new and interesting open science approaches and support my local academic community in implementing them.
I am also interested in #opendata, especially those coming from #cogneuro experiment. I think sharing human brain images (e.g.: #mri) in an effective, #privacy - and #ethics compliant way is one of the most intriguing and difficult problems of open #neuroscience to date.
I like #scicomm discussions and practices, I hope there will be a massive and effective scientific #TwitterMigration and I'll try my best to support it.
Fine tune your content and target and carefully carve your threads for presenting your work online.
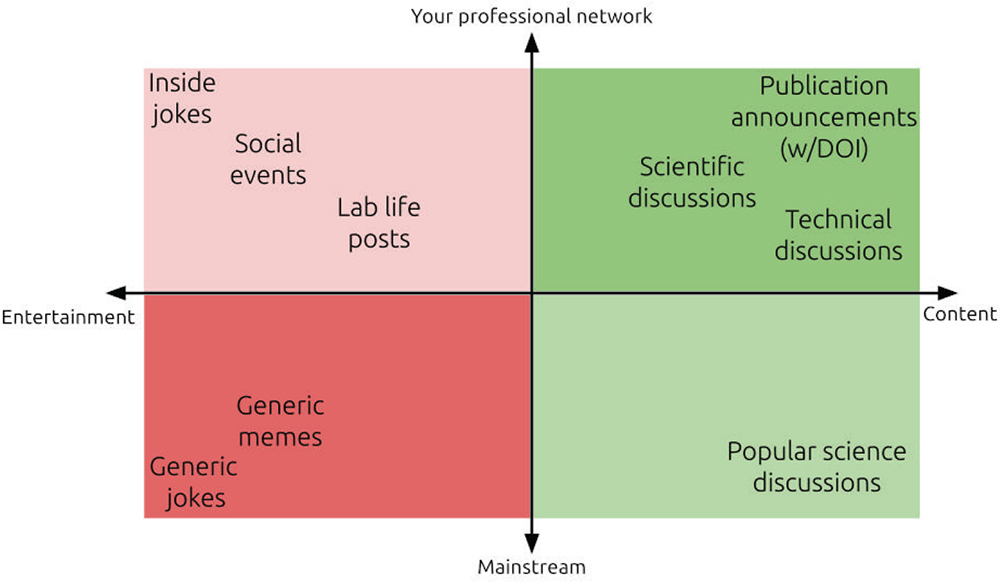
It takes time and committment to build and maintain an online professional reputation, no matter which is the platform you chose.
This is a possible way to transform the internet towards what was stated in the [Berlin Declaration](https://openaccess.mpg.de/Berlin-Declaration): a functional medium for distributing knowledge (3/3)🟨
Real life interactions, among the other things, are a way to filter out scientific outputs, in order to avoid unnecessary reading and discover fresh, original ones. Tracing the impact of these interactions was possible only via citations, losing the trace of what brought authors to that mention.
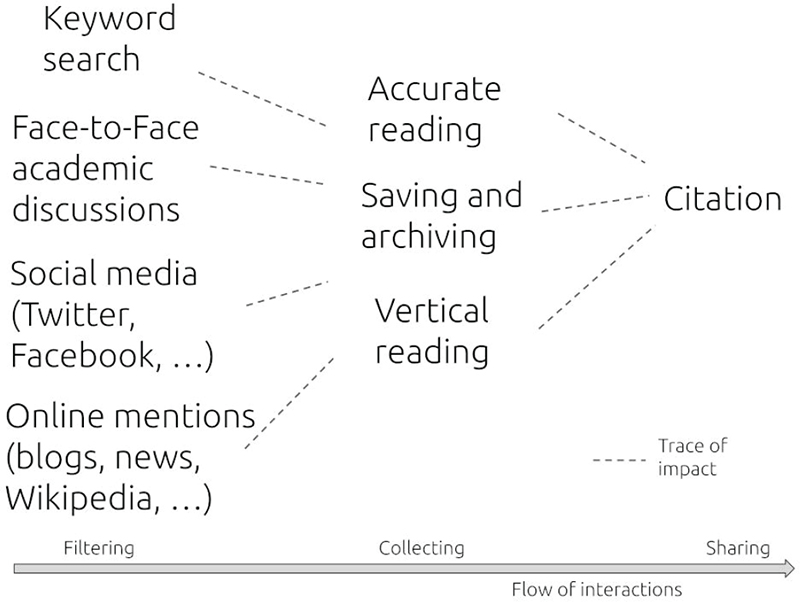
DOIs and article level metrics are a way to quantitatively reconstruct a complete trace of impact. This applies to every published output! (2/3)
Social media could be thought as tools for disrupting prestige, position and geography based barriers for scientific conversations.
A few weeks ago, right before the mastodon wave, I summarized my takes on this in [a tutorial](https://doi.org/10.33393/ao.2022.2468) for [About Open](https://journals.aboutscience.eu/index.php/aboutopen) on how to unleash the power of online tools for professional purposes in an open science environment.
Throughout the text I stressed the concept that every attempt to disseminate scientific outputs online is, above all, a scientific communication task. (1/3) 🧵
#openaccess #scicomm #altmetrics

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
RT from birdsite, account of German Reproducibility Network #GRN:
📢REMINDER: Virtual brainstorming event📢
How to build, grow and sustain a #reproducibility or #OpenScience initiative?
Don't miss it on November 22-23 🙌🏼
I've switched servers. I think qoto.org fits with the interactions and the content I would pursue with this account.
full stack technician working on #openaccess and #opendata at CIMeC - Center For Mind / Brain Sciences at The University of Trento (Italy)
founder and steering committee of the Italian Reproducibility Network
