

Nicola Romanò @nicolaromano@qoto.org
- Pronouns
- he/him
Senior lecturer at Edinburgh University and Zhejiang-Edinburgh Joint Institute (ZJE).
Undergraduate Programme Coordinator, Biomedical Informatics at ZJE.
I teach #imageanalysis & #dataanalysis with #RStats & #python.
My research is focused on how #heterogeneous behaviour in #pituitary (and other) cells shapes their function as a population.
I'm also very interested in #reproducibility and #openscience.
Joined Oct 2022
@adamhsparks @johannes_lehmann The problem with this type of issues is that you can't change things while keeping the status quo. Things need to change in academia. Number (as opposed to quality) of publications and impact factor are terrible ways of assessing whether someone should be promoted. There is so much more that should be assessed!
Quality of research, teaching, supervision of students, grants, engagement with the academic community/citizenship, engagement with the public and other research stakeholders, *real* commitment to open and reproducible research, and probably more!
This obviously requires people with power (e.g. those on promotion boards or funders) to change their mindset, but it also requires everyone to showcase, be proud and put effort towards their good practices, so that others start seeing the value in them and adopt them until they're widespread.
Things are slowly changing, but there is a lot of resistance, even in places that should be more "enlightened". The stark reality is that currently universities are run as businesses, and that is bad (I was recently asked if some research I'm doing is business critical. I don't know how I kept my cool.)
Nicola Romanò
boosted

One of the largest science funders, the Bill & Melinda Gates Foundation, will cease paying journal “article processing charges” and instead asks funded researchers to publish their work as preprints. This is fantastic. The costs of the current publishing system drain research funds and exclude too many scientists solely due to financial constraints. Funders are in a much better position to rock the “publishing” boat than researchers.
https://gatesfoundationoa.zendesk.com/hc/en-us/articles/24810787662100-Policy-Refresh-2025-Overview
@teunbrand fair enough I didn't understand the use case! (And didn't know about geom_point_raster!)
@teunbrand good solution! I would avoid overloading geom_point though, something like geom_point_raster would be more meaningful. I know you can still use ggplot2:: to access the original version but that is prone to unwanted confusion.
Nicola Romanò
boosted

Have to output a bunch of dense scatterplots to PDF/SVG, but don't want the filesize to bloat with thousands of symbols to draw the points?
Learn from my mistakes instead of making your own:
```r
geom_point <- function(...) {
ggrastr::rasterise(ggplot2::geom_point(...), dpi = 300)
}
```
#rstats
Nicola Romanò
boosted

I'm reviewing code that I wrote more than 1yr ago for a manuscript. I had a script with ~1000 lines and I just reduced it to 200 by using `purrr::map()` and my custom functions. It's crazy how if you just keep coding you eventually get better. I could go to 100-150 but I need to move on so I'll just leave it as is.
Are you based in the UK and interested in #teaching #statistics (in the #lifesciences but even outside!)? Would you like to discuss #challenges and #strategies with other people from different disciplines?
Then we invite you to a #workshop based upon a cross-UK survey of undergraduate teaching in study design and data analysis for #Biology, #Biomedical Science, #Medicine and #Psychology. The workshop aims to critically examine teaching practice with an eye on improving research reproducibility as a part of science reform.
What can you gain from the workshop?
- Cross-disciplinary perspective on the challenges faced and approaches to overcome them, and solidarity that comes from openly discussing challenges;
- Resources for teaching/to influence teaching of stats in an attendees’ own institution;
- Opportunity to benchmark your teaching programs versus those nationwide;
- Opportunity to gain “outside the box” (cross-discipline) perspective on why and how to teach study design and analysis;
- Knowledge of approaches and software people are using across UK to do/teach data analysis.
The workshop will occur *12 June*, 2024, at the University of Manchester. We anticipate the fee will be less than £20 (and will most likely be free)
Below, we provide links to (1) view the workshop's itinerary and (2) to sign up to indicate your general interest (we are gauging interest at the moment for organisational purposes; registration will follow).
Link for itinerary:
https://docs.google.com/document/d/1fj_VN3_bJ9H1kXpXqFjVqPR6Kbg5ErVFq7iKldlltu0/edit?usp=sharing
Link to indicate interest:
https://forms.office.com/e/yfTsyPe49e
============================
Organising committee:
- Crispin Jordan (University of Edinburgh)
- Nicola Romanò (University of Edinburgh)
- Kasia Banas (University of Edinburgh)
- Vanessa Armstrong (Newcastle University)
- William Kay (Cardiff University)
Nicola Romanò
boosted

@tedinski @inthehands dealing with an unpredictable support ("sometimes this will unblock a whole thing I didn't know I didn't know but sometimes this is a rabbit hole distracting me") is not a new meta skill of learning strategy. A lot of the folks I know teaching here are adapting the same meta skill building lessons for correcting misconceptions re how we learn. The hopeful side of students dealing with confusing technology imo is that it makes this stuff really immediately relevant to them.
Nicola Romanò
boosted

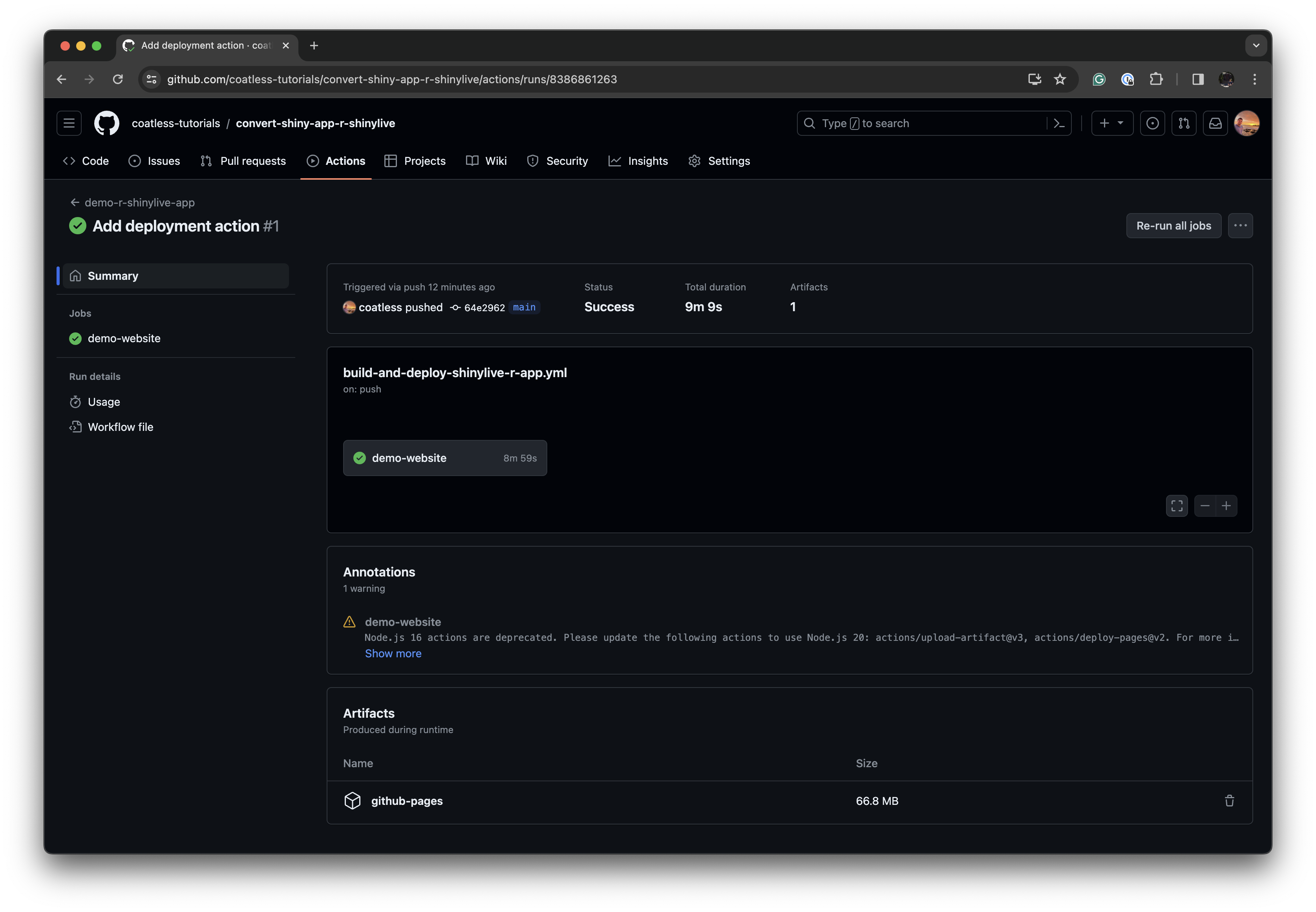
Thanks to a StackOverflow question, I've outlined a method for deploying shiny live apps straight to GitHub Pages from a repository. This approach bypasses storing the converted app within the repo by integrating a GitHub Pages deployment step into the GitHub Action worker, which keeps the repo history focused on only the shiny app source.
Check it out:
👉 https://github.com/coatless-tutorials/convert-shiny-app-r-shinylive
@ElenLeFoll This could be interesting as well https://royalsocietypublishing.org/doi/10.1098/rspb.2022.1113
Nicola Romanò
boosted

Several of us overly online biologists spent years quietly doing an experiment on Twitter, trying to find out if tweeting about new studies from a set of mid-range journals caused an increase in later citations, compared to set of untweeted control articles.
Turns out we had no noticeable effect; the tweeted papers were cited at the same rate as the control set.
Our paper, headed by Trevor Branch, was published today in PLOS One:
https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0292201
Nicola Romanò
boosted

Preprint describing Nellie, a napari plugin for automated organelle segmentation. Results look impressive!
https://arxiv.org/abs/2403.13214
repo (with video): https://github.com/aelefebv/nellie
Nicola Romanò
boosted

@neuralreckoning Do they mean it doesn't cover ALL the costs of research but only part of it? In that case, if costs are fairly constant the more overheads they charge the larger proportion of the costs is covered. That's the benign interpretation. I have the impression it's more because of rankings, prestige and such, which in turn brings more funds. It's all business. The more I learn about the more I find evidence modern academia is managed as big corporations.
Our new #preprint "Data Hazards as an ethical toolkit for neuroscience" is out!
Read it on OSF!
https://osf.io/preprints/osf/yn2j9
This is some fantastic work that has been spearheaded by a great PhD student, Susana!
She care a lot about this project and has used her PhD as a case study for applying the proposed toolkit (which will become part of her PhD project!)
Writing this was fun, and it really made us think about #ethics of #data and how we should consider these issues at all stages of a project, from planning, through to after the end of the project.
We would be thrilled to hear what you think about this!
Nicola Romanò
boosted
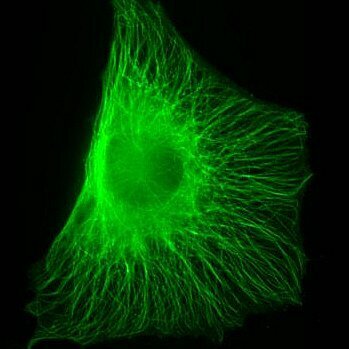
I am honestly floored at the #SegmentAnything implementation for #ImageJ / #Fiji
Even running on a laptop, once loaded, it's incredibly quick.
Moreover, it's a super-simple install which is a major barrier to many #AI #DeepLearning implementations.
Time to play around with some #Microscopy and #DigitalPathology data!
Details here: https://github.com/segment-anything-models-java/SAMJ-IJ
Photo source: https://www.pexels.com/photo/photo-of-railway-on-mountain-near-houses-1658967/
@BorisBarbour @steveroyle @andrewplested a couple of other options I used in the past (these work on Linux, not sure about Mac sorry).
Depending on how the PDF was generated some work better than others
1. use pdftk
pdftk inputfile.pdf -o outputfile.pdf compress
2. convert to postscript then back to pdf
pdf2ps inputfile.pdf output.ps
ps2pdf output.ps inputfile_small.pdf
3. use qpdf
qpdf --linearize inputfile.pdf output.pdf
@lunareclipse You could try tabula-py https://pypi.org/project/tabula-py/
Nicola Romanò
boosted
Post by Marcus Meister about @eLife ’s publishing model. Positive assessment and a plea to make “live” preprints & abandon typesetting.
https://markusmeister.com/2024/03/17/a-year-into-elifes-new-publishing-model/
Nicola Romanò
boosted

{kind=link}
{kind=link}
HOLY MACKEREL I just howled laughing. Y'all sometimes it is a pure blast to be old.
'Researchers have discovered a new way to hack AI assistants that uses a surprisingly old-school method: ASCII art. It turns out that chat-based large language models such as GPT-4 get so distracted trying to process these representations that they forget to enforce rules blocking harmful responses, such as those providing instructions for building bombs.'
@mvugt I've been doing that over the past couple of years (using Toggl Track) and it's indeed super super useful. Also, it gives you quantifiable evidence for prioritising certain activities and/or say no to others.
- Pronouns
- he/him
Senior lecturer at Edinburgh University and Zhejiang-Edinburgh Joint Institute (ZJE).
Undergraduate Programme Coordinator, Biomedical Informatics at ZJE.
I teach #imageanalysis & #dataanalysis with #RStats & #python.
My research is focused on how #heterogeneous behaviour in #pituitary (and other) cells shapes their function as a population.
I'm also very interested in #reproducibility and #openscience.
Joined Oct 2022
