

Nicola Romanò @nicolaromano@qoto.org
Senior lecturer at the Zhejiang-Edinburgh Joint Institute (ZJE) and Edinburgh University.
Undergraduate Programme Director, Biomedical Informatics at ZJE.
I teach #imageanalysis & #dataanalysis with #RStats & #python. I study #heterogeneity in #pituitary (and other) cells.
I'm also very interested in #reproducibility and #openscience.
Joined Oct 2022
Nicola Romanò
boosted

Nature news is really shooting itself in the foot - whenever I save an article and only get to reading it >14 days later, it's paywalled 🧱
Once again: Reliable information gets paywalled where misinformation is available for free.
Nicola Romanò
boosted

Okay, it's been a while since I last did this, and I haven't done it on mastodon yet, so I'm going to take a deep dive into p-values for another automated GWAS. Specifically, this one, relating to "Eosinophil percentage":
https://twitter.com/SbotGwa/status/1622218396661071874
I'm interested in this particular set of results because the p-values are impossibly large, with dozens of impossibly-large p-value peaks throughout the genome.
Also, the heritability of 0.22 is within the realm of possibility for finding true links.
Nicola Romanò
boosted

@ct_bergstrom Not sure what's this rant about. Nobody ever said decoder models are perfect or will have an actual understanding of the world. (Ok, maybe except for that one Google guy) OpenAI released a beta product which is incredibly helpful if used correctly but people like you just focus on its mistakes. It's like hating on cars because they can't take the stairs.
Nicola Romanò
boosted

@ct_bergstrom The LLM isn't bullshitting, because it's just a machine. It has no intentionality and no mind.
The engineers and execs at tech companies who are leveraging LLMs: they are bullshitting. It's an act of malice and should be treated as such.
Nicola Romanò
boosted

@ct_bergstrom Disagree. They're designed to mimic what a human would write. If they end up bullshitting it's because the models aren't good enough, not because that's what they're designed to do.
Nicola Romanò
boosted

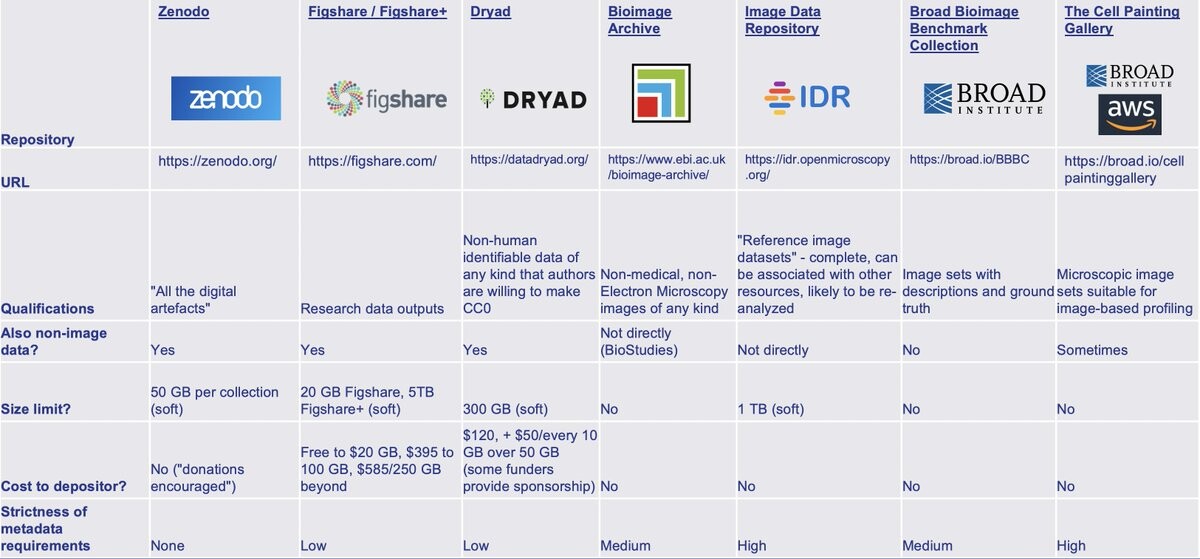
Have you got data and not sure where to deposit? Look at the helpful table by @CiminiLab for image archives.
#imageAnalysis #microscopy #openScience
---
RT @CiminiLab
@Romain_BioImage I recently generated this table, if it helps! I think the BioimageArchive would be good for images
https://twitter.com/CiminiLab/status/1616508224571641856
Nicola Romanò
boosted

= Sharing peer review publicly? =
In a discussion with non-academics there was a consensus that us not sharing our peer review process publicly violates what they perceive as our scientific integrity & our commitment to them as key stakeholders and indirect funders.
My reply: yes, I agree.
Question 👇
Nicola Romanò
boosted

@brewsterkahle Not just avoiding paywalls, but also avoiding the encumbrance of getting access via all those different publisher interfaces, I reckon.
Nicola Romanò
boosted

@villavelius @brewsterkahle yes! as far as I know, sci-hub is the only way to get PDFs by DOI via a proper API that you can use on the command line or in Python scripts (e.g. https://pypi.org/project/scidownl/ ). obviously this is really practical or even a necessity for larger-scale systematic literature research. so even if the publication is open-access or you have official access in some other way, sci-hub can just be much more practical to use.
Nicola Romanò
boosted

“I dashed out to grab some drugstore makeup to paint our faces with insignia from Cars and Star Wars. The random blocks of bright white, iridescent gold, and thick blues and reds reminded me of the Zinc sunscreen my own mother painted on my face for our Disney trips in the 1980s. She was protecting us from sunburn, I was warding off facial recognition systems.” — @cyberlyra
Nicola Romanò
boosted

Here's an analysis I have done on editorial processing times in Hindawi special issues; https://psyarxiv.com/6mbgv. I think there's v circumstantial evidence for paper mill infestation.
Nicola Romanò
boosted

Hello world! 📢
The #Bioconductor EuroBioc 2023 conference will be in Ghent, Belgium 🇧🇪 on the 20, 21, 22 September 2023. More details, including keynote speakers and calendar at https://eurobioc2023.bioconductor.org/
Oh, and abstract submissions are already open!
Nicola Romanò
boosted

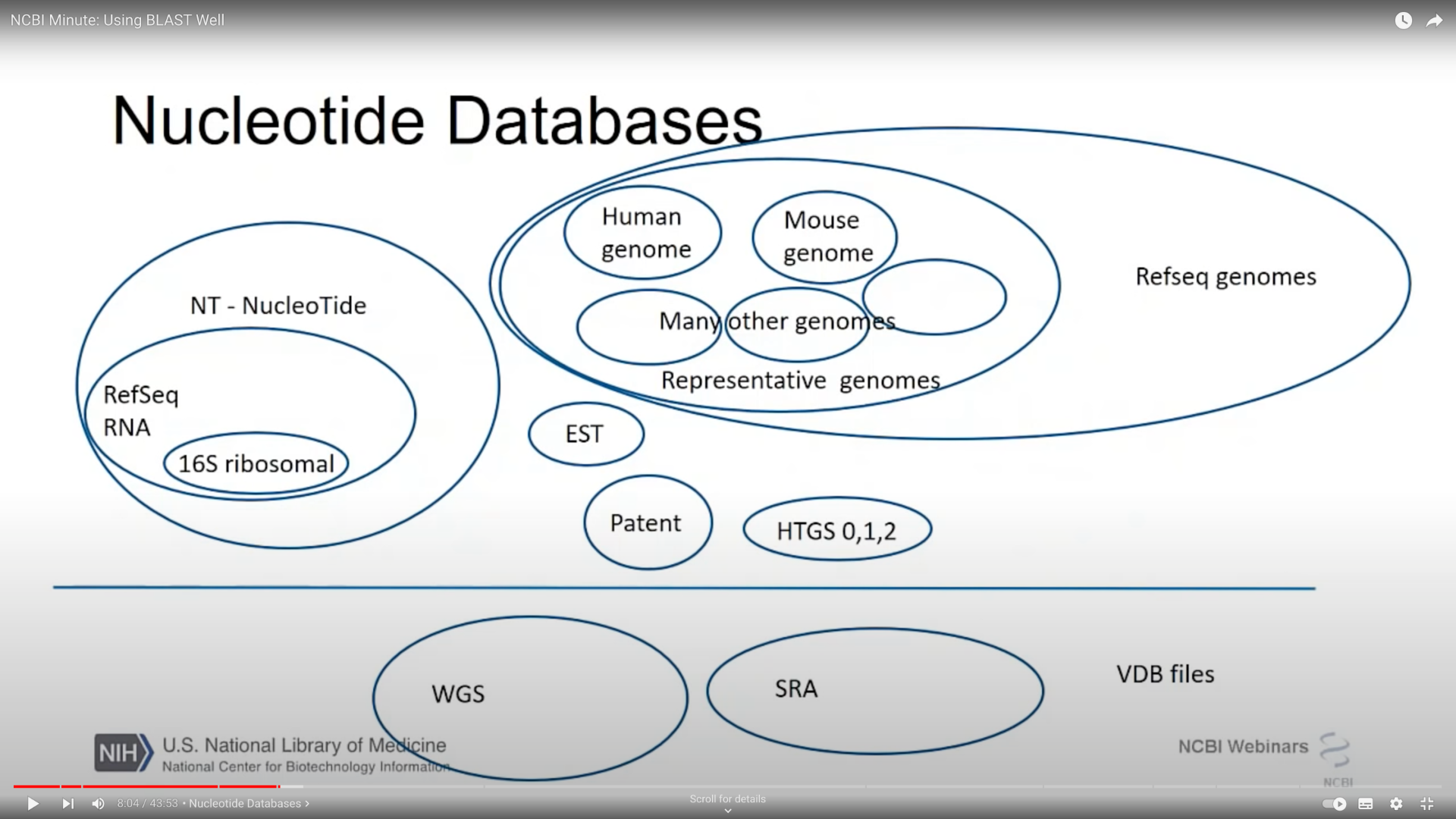
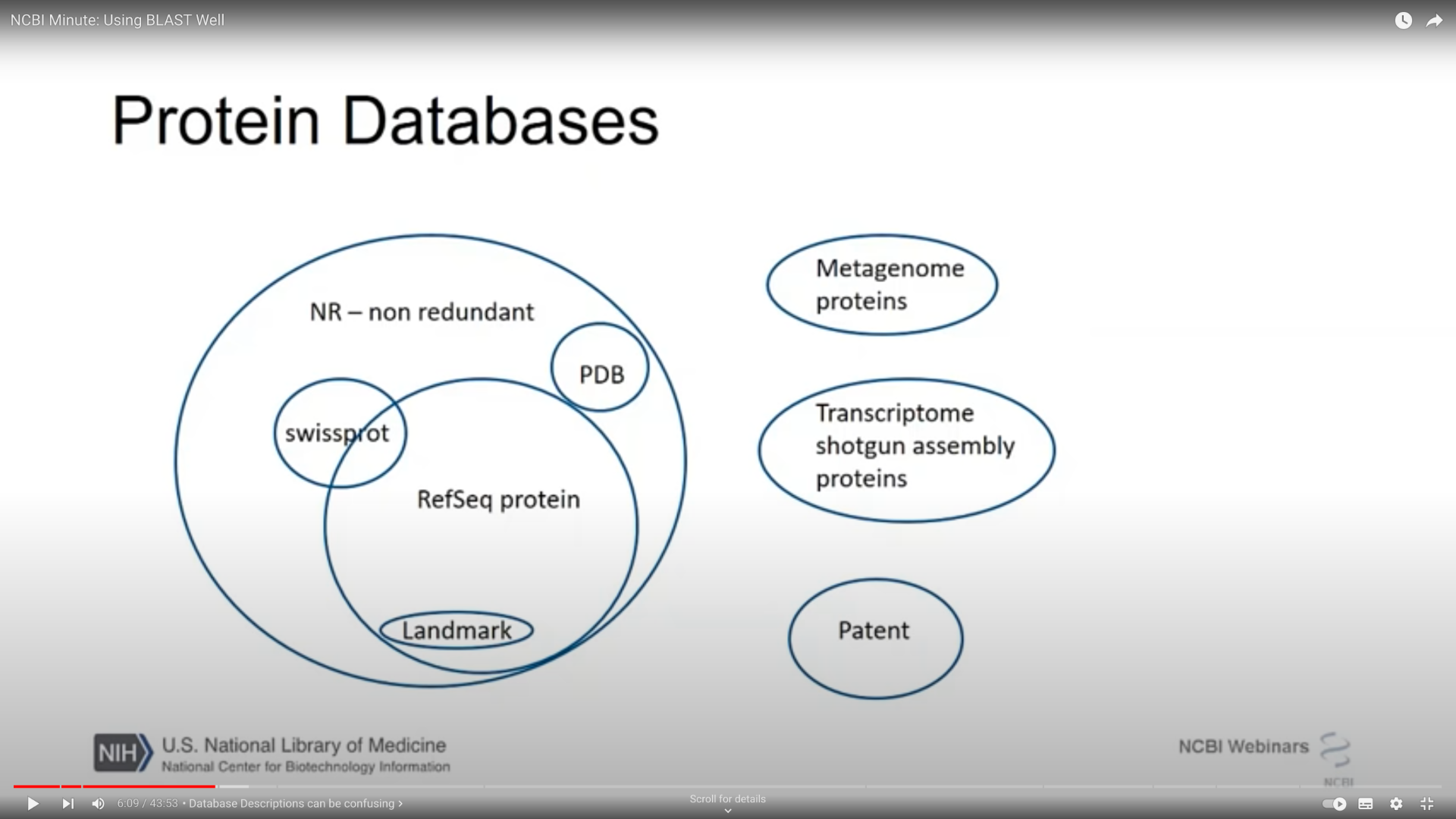
If you've ever wondered EXACTLY what is in
@NCBI
nt and nr (I certainly have!)
From https://youtu.be/2FW1dk5YQ3I?t=484 and https://youtu.be/KLBE0AuH-Sk?t=692 (cued to the right spots in the video)
Nicola Romanò
boosted

𝚖𝚊𝚛𝚐𝚒𝚗𝚊𝚕𝚎𝚏𝚏𝚎𝚌𝚝𝚜 0.9.0 is a BIG📦release! Simple yet powerful tools to help you interpret the results of over 70 classes of models in #RStats (GLM, GAM, discrete choice, mixed-effects, bayesian, etc.) 🧵 on some cool new stuff. https://vincentarelbundock.github.io/marginaleffects/
One #vscode feature that can be annoying or extremely useful, depending on your workflow, is that when you click on a file in your project, it is open in "preview mode". The file won't stay open and the tab will be reused to open any other file you click on unless you modify it.
I just discovered that you can either:
- double click on the file to open it persistently
- change the workbench.editor.enablePreview
parameter in the settings to disable preview altogether! (there are specific settings workbench.editor.enablePreviewFromQuickOpen and workbench.editor.enablePreviewFromCodeNavigation if you want to control preview mode only in specific cases)
Nicola Romanò
boosted

Lots to like in the new #dplyr 1.1.0 release (which just hit CRAN). Obviously the new data.table-inspired `.by` and non-equi joins are highlights. But I just re-ran some standard benchmarks on my machine and its definitely faster too. E.g. A big grouped collapse on some NYC taxi data is about twice as fast as it used to be. #rstats
Nicola Romanò
boosted

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Investigating the Complexity of Gene Co-expression Estimation for Single-cell Data https://www.biorxiv.org/content/10.1101/2023.01.24.525447v1?med=mas
Nicola Romanò
boosted
Path analysis reveals that corticosterone mediates gluconeogenesis from fat-derived substrates during acute stress in songbirds https://www.biorxiv.org/content/10.1101/2023.01.24.525409v1?med=mas
Senior lecturer at the Zhejiang-Edinburgh Joint Institute (ZJE) and Edinburgh University.
Undergraduate Programme Director, Biomedical Informatics at ZJE.
I teach #imageanalysis & #dataanalysis with #RStats & #python. I study #heterogeneity in #pituitary (and other) cells.
I'm also very interested in #reproducibility and #openscience.
Joined Oct 2022
