

Nicola Romanò @nicolaromano@qoto.org
Senior lecturer at the Zhejiang-Edinburgh Joint Institute (ZJE) and Edinburgh University.
Undergraduate Programme Coordinator, Biomedical Informatics at ZJE.
I teach #imageanalysis & #dataanalysis with #RStats & #python. I study #heterogeneity in #pituitary (and other) cells.
I'm also very interested in #reproducibility and #openscience.
Joined Oct 2022
Are you based in the UK and interested in #teaching #statistics (in the #lifesciences but even outside!)? Would you like to discuss #challenges and #strategies with other people from different disciplines?
Then we invite you to a #workshop based upon a cross-UK survey of undergraduate teaching in study design and data analysis for #Biology, #Biomedical Science, #Medicine and #Psychology. The workshop aims to critically examine teaching practice with an eye on improving research reproducibility as a part of science reform.
What can you gain from the workshop?
- Cross-disciplinary perspective on the challenges faced and approaches to overcome them, and solidarity that comes from openly discussing challenges;
- Resources for teaching/to influence teaching of stats in an attendees’ own institution;
- Opportunity to benchmark your teaching programs versus those nationwide;
- Opportunity to gain “outside the box” (cross-discipline) perspective on why and how to teach study design and analysis;
- Knowledge of approaches and software people are using across UK to do/teach data analysis.
The workshop will occur *12 June*, 2024, at the University of Manchester. We anticipate the fee will be less than £20 (and will most likely be free)
Below, we provide links to (1) view the workshop's itinerary and (2) to sign up to indicate your general interest (we are gauging interest at the moment for organisational purposes; registration will follow).
Link for itinerary:
https://docs.google.com/document/d/1fj_VN3_bJ9H1kXpXqFjVqPR6Kbg5ErVFq7iKldlltu0/edit?usp=sharing
Link to indicate interest:
https://forms.office.com/e/yfTsyPe49e
============================
Organising committee:
- Crispin Jordan (University of Edinburgh)
- Nicola Romanò (University of Edinburgh)
- Kasia Banas (University of Edinburgh)
- Vanessa Armstrong (Newcastle University)
- William Kay (Cardiff University)
Nicola Romanò
boosted

@tedinski @inthehands dealing with an unpredictable support ("sometimes this will unblock a whole thing I didn't know I didn't know but sometimes this is a rabbit hole distracting me") is not a new meta skill of learning strategy. A lot of the folks I know teaching here are adapting the same meta skill building lessons for correcting misconceptions re how we learn. The hopeful side of students dealing with confusing technology imo is that it makes this stuff really immediately relevant to them.
Nicola Romanò
boosted

Thanks to a StackOverflow question, I've outlined a method for deploying shiny live apps straight to GitHub Pages from a repository. This approach bypasses storing the converted app within the repo by integrating a GitHub Pages deployment step into the GitHub Action worker, which keeps the repo history focused on only the shiny app source.
Check it out:
👉 https://github.com/coatless-tutorials/convert-shiny-app-r-shinylive
Nicola Romanò
boosted

Several of us overly online biologists spent years quietly doing an experiment on Twitter, trying to find out if tweeting about new studies from a set of mid-range journals caused an increase in later citations, compared to set of untweeted control articles.
Turns out we had no noticeable effect; the tweeted papers were cited at the same rate as the control set.
Our paper, headed by Trevor Branch, was published today in PLOS One:
https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0292201
Nicola Romanò
boosted

Preprint describing Nellie, a napari plugin for automated organelle segmentation. Results look impressive!
https://arxiv.org/abs/2403.13214
repo (with video): https://github.com/aelefebv/nellie
Nicola Romanò
boosted

@neuralreckoning Do they mean it doesn't cover ALL the costs of research but only part of it? In that case, if costs are fairly constant the more overheads they charge the larger proportion of the costs is covered. That's the benign interpretation. I have the impression it's more because of rankings, prestige and such, which in turn brings more funds. It's all business. The more I learn about the more I find evidence modern academia is managed as big corporations.
Our new #preprint "Data Hazards as an ethical toolkit for neuroscience" is out!
Read it on OSF!
https://osf.io/preprints/osf/yn2j9
This is some fantastic work that has been spearheaded by a great PhD student, Susana!
She care a lot about this project and has used her PhD as a case study for applying the proposed toolkit (which will become part of her PhD project!)
Writing this was fun, and it really made us think about #ethics of #data and how we should consider these issues at all stages of a project, from planning, through to after the end of the project.
We would be thrilled to hear what you think about this!
Nicola Romanò
boosted

I am honestly floored at the #SegmentAnything implementation for #ImageJ / #Fiji
Even running on a laptop, once loaded, it's incredibly quick.
Moreover, it's a super-simple install which is a major barrier to many #AI #DeepLearning implementations.
Time to play around with some #Microscopy and #DigitalPathology data!
Details here: https://github.com/segment-anything-models-java/SAMJ-IJ
Photo source: https://www.pexels.com/photo/photo-of-railway-on-mountain-near-houses-1658967/
Nicola Romanò
boosted
Post by Marcus Meister about @eLife ’s publishing model. Positive assessment and a plea to make “live” preprints & abandon typesetting.
https://markusmeister.com/2024/03/17/a-year-into-elifes-new-publishing-model/
Nicola Romanò
boosted

HOLY MACKEREL I just howled laughing. Y'all sometimes it is a pure blast to be old.
'Researchers have discovered a new way to hack AI assistants that uses a surprisingly old-school method: ASCII art. It turns out that chat-based large language models such as GPT-4 get so distracted trying to process these representations that they forget to enforce rules blocking harmful responses, such as those providing instructions for building bombs.'
Nicola Romanò
boosted

An experience of time tracking as a scientist https://www.nature.com/articles/d41586-024-00806-1
Nicola Romanò
boosted

I just did some primary-school level investigative work using Google Scholar to find out whether the use of generative #AI is genuinely a widespread issue in #AcademicPublishing and, within five minutes, I have cause for despair... 😲 #AcWri #AcademicChatter
Nicola Romanò
boosted

"If you want to minimize the possibility of unexpected breakthroughs, tell [scientists] they will receive no resources at all unless they spend the bullk of their time competing against each other to convince you they already know what they are going to discover." - David Grabber, The Utopia of Rules.
Nicola Romanò
boosted

Exploring @eb's blog and oh my god how does this post have less than a hundred visits
Nicola Romanò
boosted

Were #hiring! We're looking for a #postdoc in #machinelearning for unsupervised learning of large-scale high-dimensional biological data. Know anyone who would be interested? Last day to apply is March 31, 2024. https://www.umu.se/en/work-with-us/open-positions/postdoctoral-position-2-years-in-machine-learning-for-analysis-of-large-scale-high-dimensional-biological-data_707668/
ComPromptMized: Unleashing Zero-click Worms that Target GenAI-Powered Applications
https://sites.google.com/view/compromptmized
Paper here https://arxiv.org/abs/2403.02817
#generativeAI #worm #virus #attack #chatgpt #gemini #ai #adversarial
Nicola Romanò
boosted

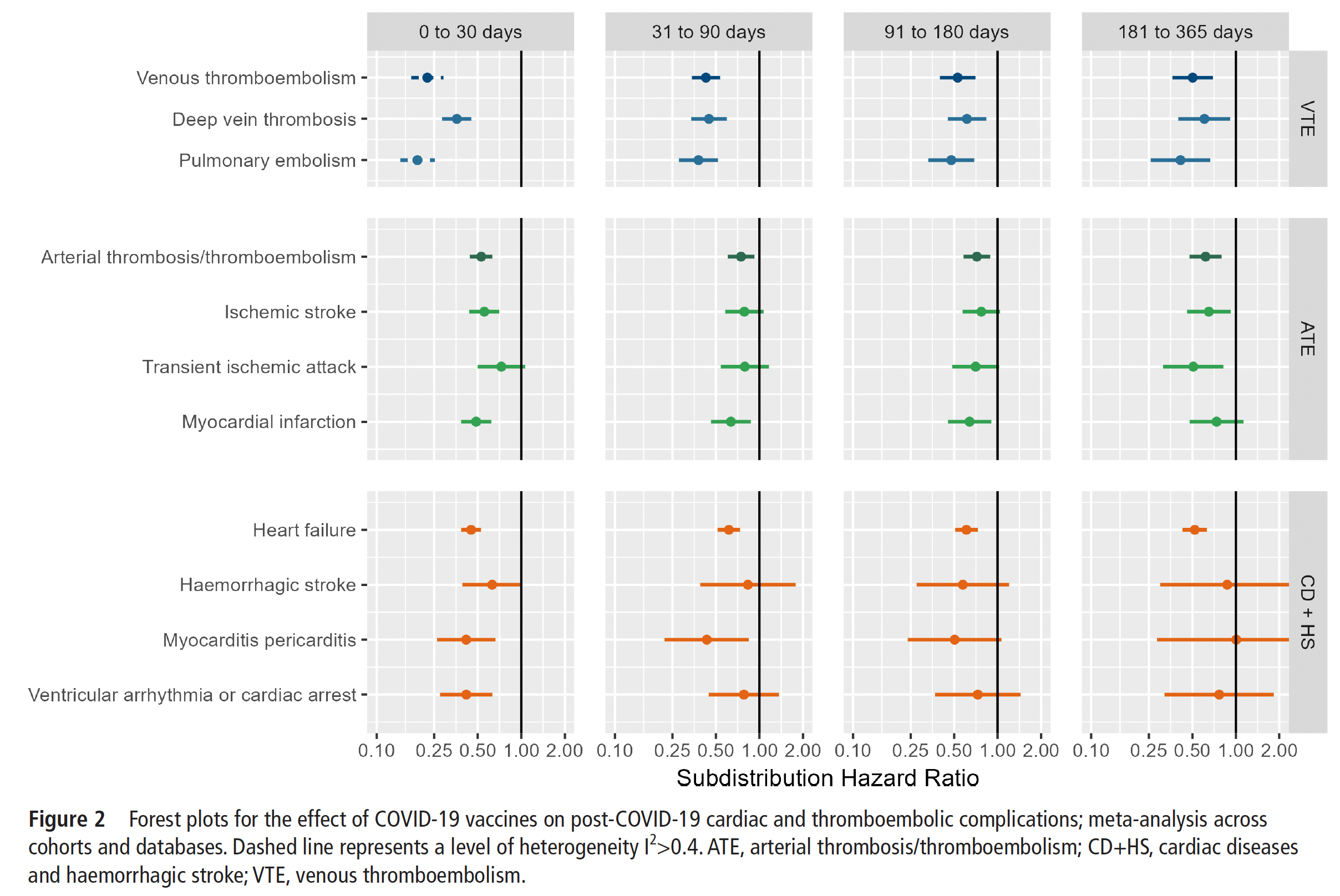
Covid vaccination markedly reduced blood clots, heart attacks, heart failure, stroke and other adverse cardiovascular outcomes, as seen from over 20 million people, about half of whom were vaccinated https://heart.bmj.com/content/early/2024/01/24/heartjnl-2023-323483
Nicola Romanò
boosted

Folks this #LexisNexis risk assessment product that vacuums up all automotive data and uses it to raise your insurance rates is none other than the offspring of #RELX, parent of #Elsevier. Far from being an isolated product unrelated to scholarly publishing, year after year in their promotional material they boast how these are integrated systems at both a technical and operational level - your prestige publications fund this, and your professional metrics sold via SciVal are part of the same pool of data.
Who wants to bet that funders wont blink at an "aggregated funding risk score that draws from our proprietary analytics data for a whole-researcher productivity profile." We're beyond surveillance conspiracy theories, these products are here today, and every prestige publication makes us complicit and digs the grave for our own profession.
Nicola Romanò
boosted

Administrative staff increased by 17% from 2005 to 2012, while permanent scientist positions increased only by 0.04%. Total teaching staff did not match the increase in students of 25% and the precariously employed scientists increased by a whopping 50%: for every permanent scientific position, about 10 fixed term positions were created, increasing the already unhealthy competition among the academic precariat to insane levels.
3/4
Nicola Romanò
boosted

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Short-term and short-sighted reputation management.
Senior lecturer at the Zhejiang-Edinburgh Joint Institute (ZJE) and Edinburgh University.
Undergraduate Programme Coordinator, Biomedical Informatics at ZJE.
I teach #imageanalysis & #dataanalysis with #RStats & #python. I study #heterogeneity in #pituitary (and other) cells.
I'm also very interested in #reproducibility and #openscience.
Joined Oct 2022
