

Nicola Romanò @nicolaromano@qoto.org
Senior lecturer at the Zhejiang-Edinburgh Joint Institute (ZJE) and Edinburgh University.
Undergraduate Programme Director, Biomedical Informatics at ZJE.
I teach #imageanalysis & #dataanalysis with #RStats & #python. I study #heterogeneity in #pituitary (and other) cells.
I'm also very interested in #reproducibility and #openscience.
Joined Oct 2022
Nicola Romanò
boosted

@nicolaromano Exactly! The specific language is less important than the ability to write dependable and understandable code. R wasn't developed as a general purpose programming language and it's not fair to judge it that way (Python on the other hand...). Even then, the R community adapted the language and practice to better support making standalone applications, to make documentation and testing easier, etc. There's at least movement in a good direction. Excel just keeps adding less and less useful features without addressing any of its core shortcomings. Excel doesn't improve, it just gets bigger and its UI keeps churning.
Nicola Romanò
boosted
It's only Monday and I'm already done with this week. I watched a work issue turn increasingly acromonious over either miscommunication, misunderstanding procedure, or being too wed to a tool to admit it's problematic. I drafted about half a sentence in chat, then stopped because I didn't think I was adding anything necessary and didn't want to make conflict any worse.
I'm increasingly convinced that Excel spreadsheet files should self-destruct or become permanently read-only after 90 days. That's plenty of time to migrate data into a proper database or to migrate calculations into a programming language amenable to auditing, verification, and change control. Excel should be treated as an attractive hazard with a time limit on how long an unverifiable and hostile-to-revision-control worksheet should be suffered to live.
Sadly, these two thoughts are related. Spreadsheets in their current form are too dangerous to be used for engineering work.
Nicola Romanò
boosted

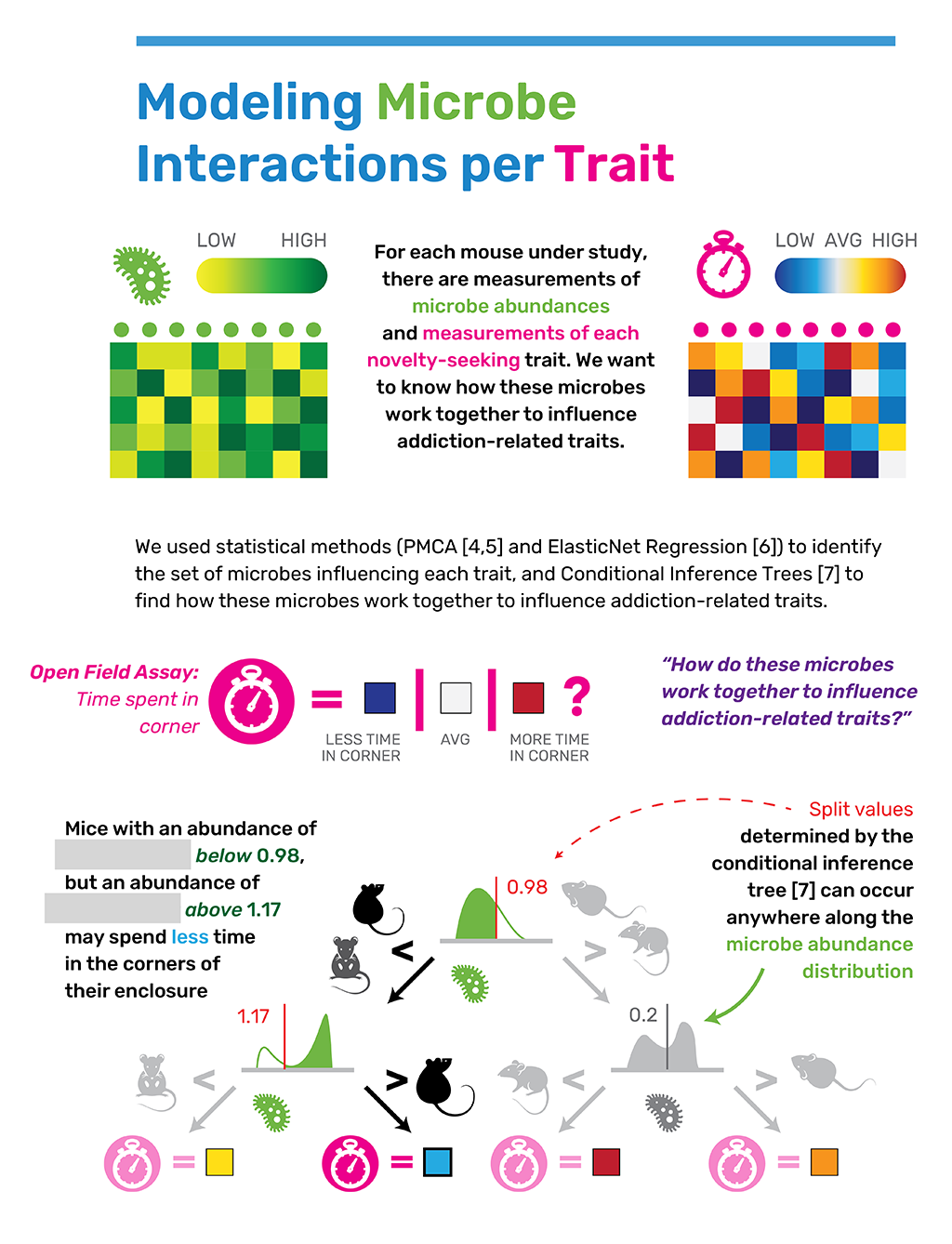
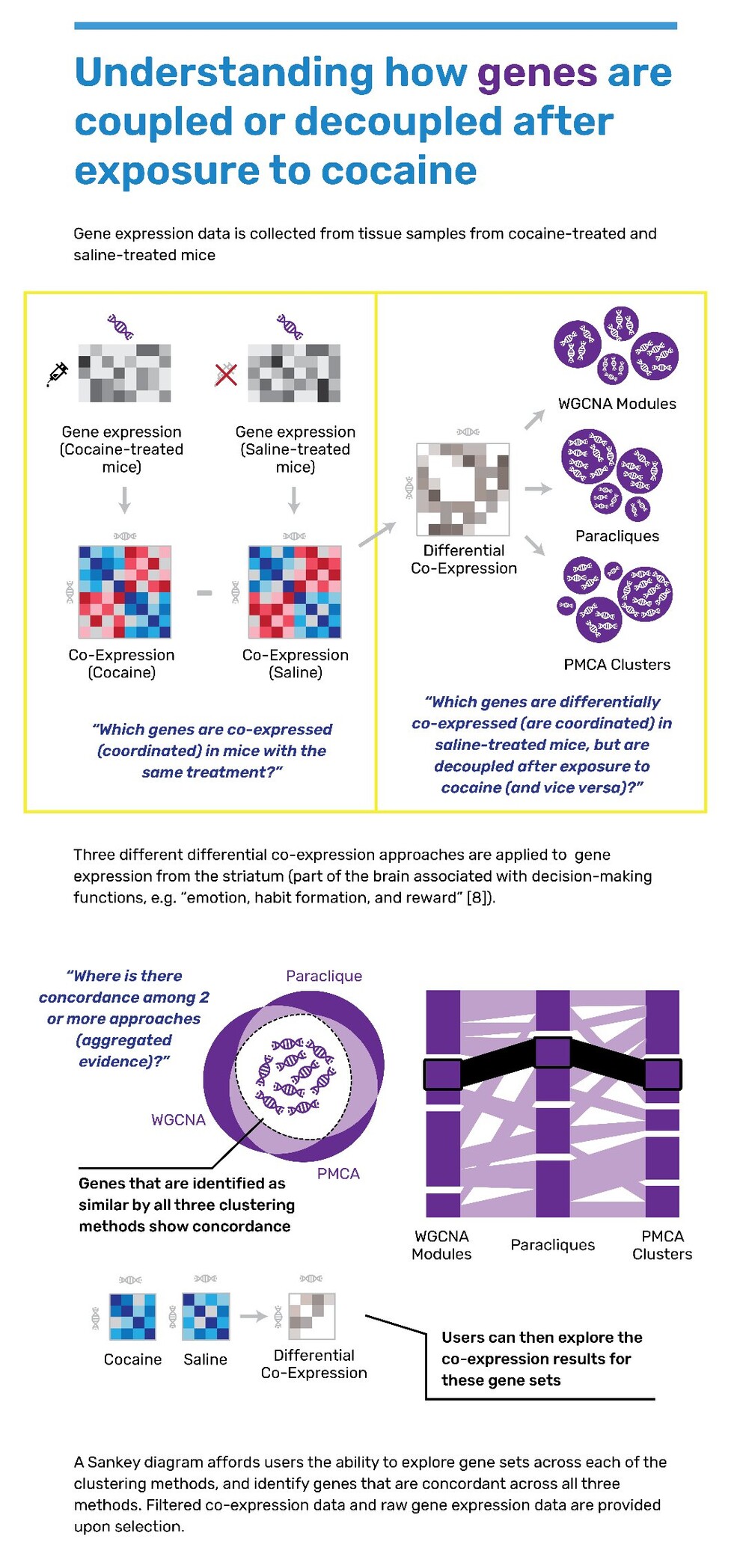
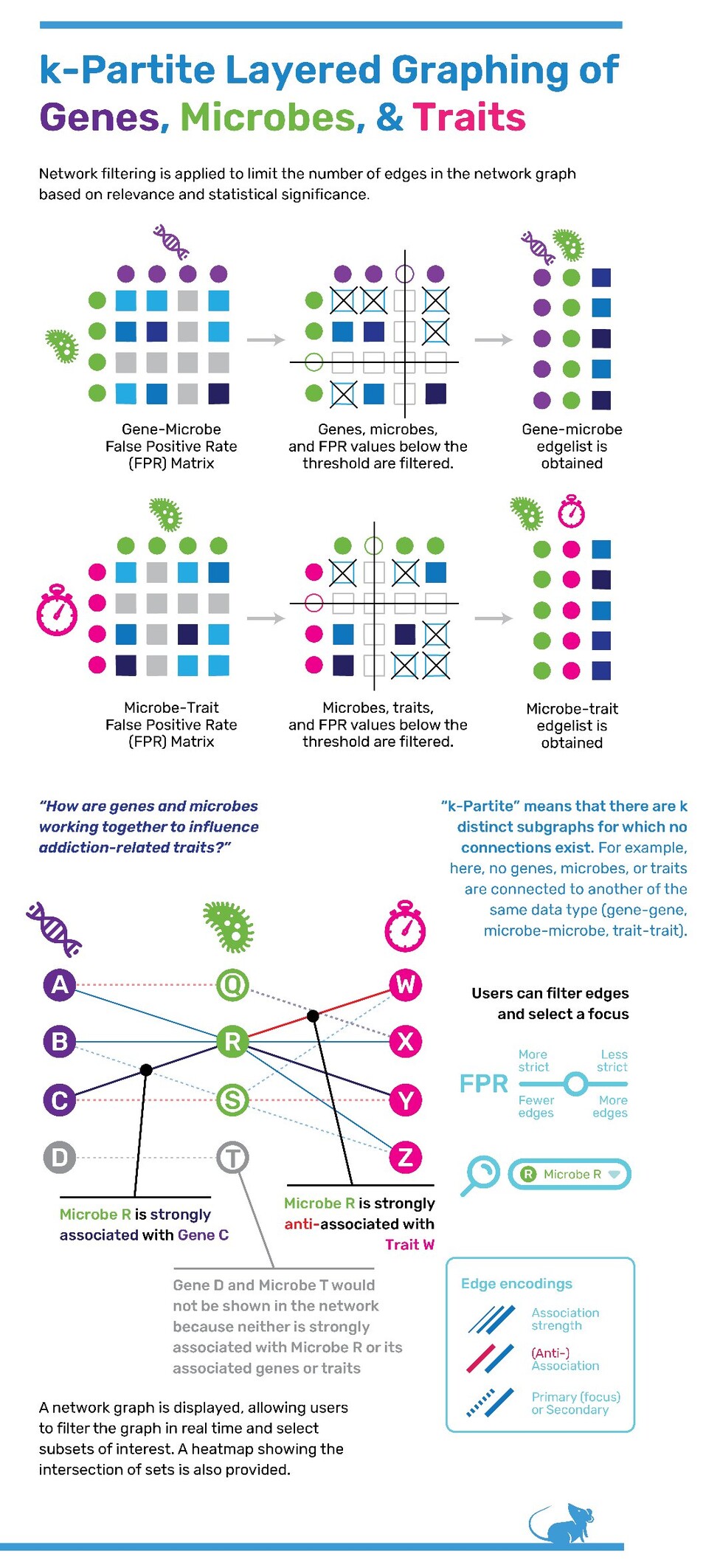
I finished my summer internship this week! I spent 4 months working with a team of biologists and statisticians at The Jackson Laboratory, building visualization software for their research needs. The lab I worked with focuses on analyzing genetics, the microbiome, and addiction-related traits. Here's an overview of some of the EDA tools I built for them in #Python ☺️ #genetics #biology #addiction #dataviz #computerscience #research #phd
If you're doing cool work with data vis + bio, lmk!
Nicola Romanò
boosted

Black hat hackers demo keycard vulnerability in millions of hotel rooms worldwide:
"They merely tap those two cards on a lock, the first rewrites a certain piece of the lock's data, and the second opens it."
Interesting read. Time to change the hotel lock tech? Again?
https://www.wired.com/story/saflok-hotel-lock-unsaflok-hack-technique/
#Security #Hacking #Travel
Nicola Romanò
boosted

A small rant about zombie ideas and the tendency to keep looking for modifications of study methods to avoid concluding that a null result is really null. http://deevybee.blogspot.com/2024/03/just-make-it-stop-when-will-we-say-that.html
#research #nullresults #laterality #handedness #publicationbias
Nicola Romanò
boosted

I've been writing serverside SQLite applications for several years now and I still picked things up from this article, which is extremely good. https://kerkour.com/sqlite-for-servers
Nicola Romanò
boosted

@futurebird Someone once told me "It's not Kafkaesque to wake up an insect. If you wake up an insect and your first thought is that this might make you late for work...*that* is Kafkaesque." That completely changed my perspective on a lot of things.
Nicola Romanò
boosted

Excellent piece from Grégory Miras on why new tools that change #accents in real time are harmful and problematic - they erase diversity - and make us less able to appreciate and listen to that diversity.
https://theconversation.com/why-ai-software-softening-accents-is-problematic-197751
Nicola Romanò
boosted

Metrics reloaded. "A comprehensive framework guiding researchers in the problem-aware selection of metrics."
A must-read for everyone doing #ImageAnalysis in #biology
https://arxiv.org/abs/2206.01653
Nicola Romanò
boosted

One of the largest science funders, the Bill & Melinda Gates Foundation, will cease paying journal “article processing charges” and instead asks funded researchers to publish their work as preprints. This is fantastic. The costs of the current publishing system drain research funds and exclude too many scientists solely due to financial constraints. Funders are in a much better position to rock the “publishing” boat than researchers.
https://gatesfoundationoa.zendesk.com/hc/en-us/articles/24810787662100-Policy-Refresh-2025-Overview
Nicola Romanò
boosted

Have to output a bunch of dense scatterplots to PDF/SVG, but don't want the filesize to bloat with thousands of symbols to draw the points?
Learn from my mistakes instead of making your own:
```r
geom_point <- function(...) {
ggrastr::rasterise(ggplot2::geom_point(...), dpi = 300)
}
```
#rstats
Nicola Romanò
boosted

I'm reviewing code that I wrote more than 1yr ago for a manuscript. I had a script with ~1000 lines and I just reduced it to 200 by using `purrr::map()` and my custom functions. It's crazy how if you just keep coding you eventually get better. I could go to 100-150 but I need to move on so I'll just leave it as is.
Are you based in the UK and interested in #teaching #statistics (in the #lifesciences but even outside!)? Would you like to discuss #challenges and #strategies with other people from different disciplines?
Then we invite you to a #workshop based upon a cross-UK survey of undergraduate teaching in study design and data analysis for #Biology, #Biomedical Science, #Medicine and #Psychology. The workshop aims to critically examine teaching practice with an eye on improving research reproducibility as a part of science reform.
What can you gain from the workshop?
- Cross-disciplinary perspective on the challenges faced and approaches to overcome them, and solidarity that comes from openly discussing challenges;
- Resources for teaching/to influence teaching of stats in an attendees’ own institution;
- Opportunity to benchmark your teaching programs versus those nationwide;
- Opportunity to gain “outside the box” (cross-discipline) perspective on why and how to teach study design and analysis;
- Knowledge of approaches and software people are using across UK to do/teach data analysis.
The workshop will occur *12 June*, 2024, at the University of Manchester. We anticipate the fee will be less than £20 (and will most likely be free)
Below, we provide links to (1) view the workshop's itinerary and (2) to sign up to indicate your general interest (we are gauging interest at the moment for organisational purposes; registration will follow).
Link for itinerary:
https://docs.google.com/document/d/1fj_VN3_bJ9H1kXpXqFjVqPR6Kbg5ErVFq7iKldlltu0/edit?usp=sharing
Link to indicate interest:
https://forms.office.com/e/yfTsyPe49e
============================
Organising committee:
- Crispin Jordan (University of Edinburgh)
- Nicola Romanò (University of Edinburgh)
- Kasia Banas (University of Edinburgh)
- Vanessa Armstrong (Newcastle University)
- William Kay (Cardiff University)
Nicola Romanò
boosted

@tedinski @inthehands dealing with an unpredictable support ("sometimes this will unblock a whole thing I didn't know I didn't know but sometimes this is a rabbit hole distracting me") is not a new meta skill of learning strategy. A lot of the folks I know teaching here are adapting the same meta skill building lessons for correcting misconceptions re how we learn. The hopeful side of students dealing with confusing technology imo is that it makes this stuff really immediately relevant to them.
Nicola Romanò
boosted

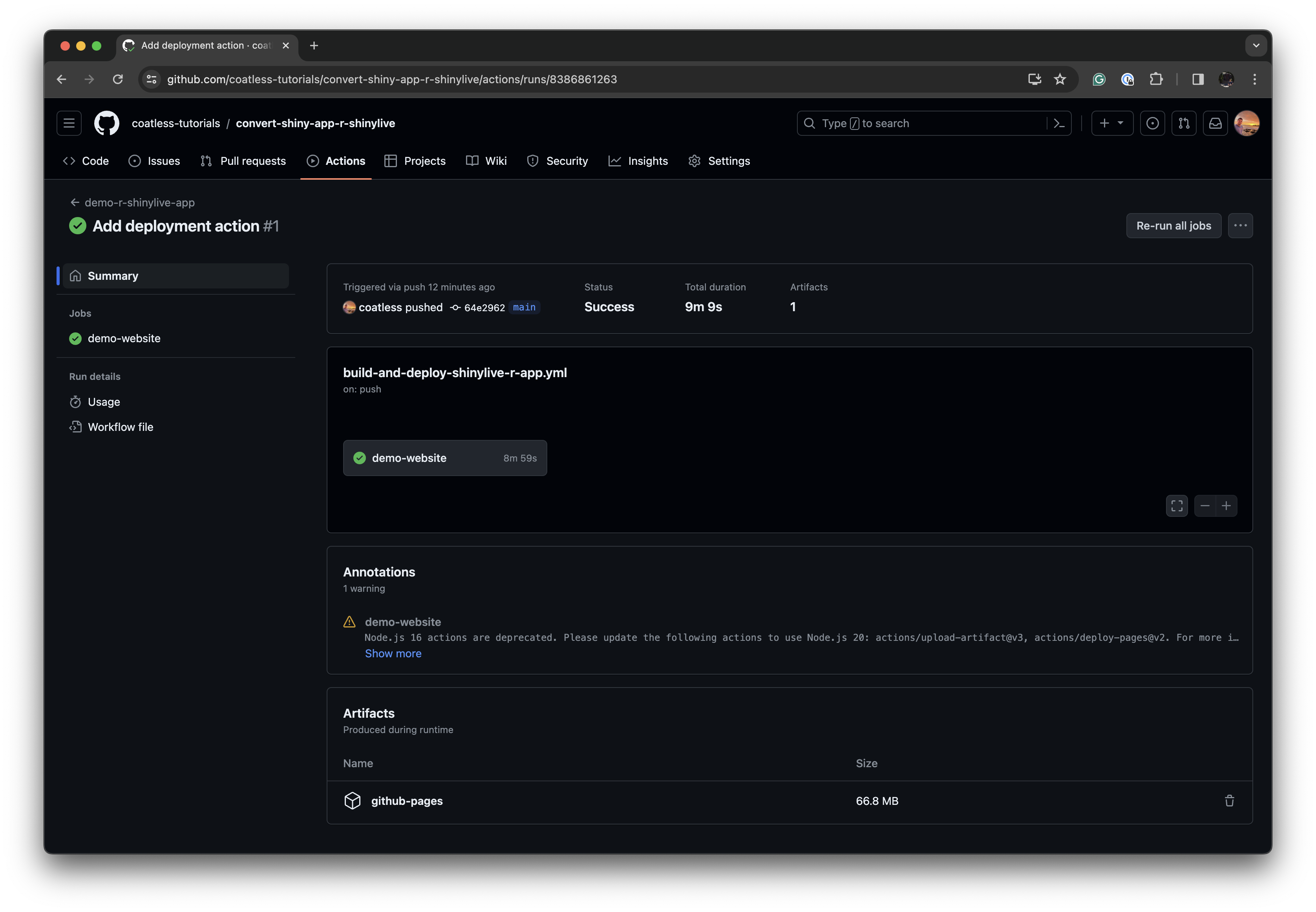
Thanks to a StackOverflow question, I've outlined a method for deploying shiny live apps straight to GitHub Pages from a repository. This approach bypasses storing the converted app within the repo by integrating a GitHub Pages deployment step into the GitHub Action worker, which keeps the repo history focused on only the shiny app source.
Check it out:
👉 https://github.com/coatless-tutorials/convert-shiny-app-r-shinylive
Nicola Romanò
boosted

Several of us overly online biologists spent years quietly doing an experiment on Twitter, trying to find out if tweeting about new studies from a set of mid-range journals caused an increase in later citations, compared to set of untweeted control articles.
Turns out we had no noticeable effect; the tweeted papers were cited at the same rate as the control set.
Our paper, headed by Trevor Branch, was published today in PLOS One:
https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0292201
Nicola Romanò
boosted

Preprint describing Nellie, a napari plugin for automated organelle segmentation. Results look impressive!
https://arxiv.org/abs/2403.13214
repo (with video): https://github.com/aelefebv/nellie
Nicola Romanò
boosted

@neuralreckoning Do they mean it doesn't cover ALL the costs of research but only part of it? In that case, if costs are fairly constant the more overheads they charge the larger proportion of the costs is covered. That's the benign interpretation. I have the impression it's more because of rankings, prestige and such, which in turn brings more funds. It's all business. The more I learn about the more I find evidence modern academia is managed as big corporations.
Our new #preprint "Data Hazards as an ethical toolkit for neuroscience" is out!
Read it on OSF!
https://osf.io/preprints/osf/yn2j9
This is some fantastic work that has been spearheaded by a great PhD student, Susana!
She care a lot about this project and has used her PhD as a case study for applying the proposed toolkit (which will become part of her PhD project!)
Writing this was fun, and it really made us think about #ethics of #data and how we should consider these issues at all stages of a project, from planning, through to after the end of the project.
We would be thrilled to hear what you think about this!
Nicola Romanò
boosted

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
I am honestly floored at the #SegmentAnything implementation for #ImageJ / #Fiji
Even running on a laptop, once loaded, it's incredibly quick.
Moreover, it's a super-simple install which is a major barrier to many #AI #DeepLearning implementations.
Time to play around with some #Microscopy and #DigitalPathology data!
Details here: https://github.com/segment-anything-models-java/SAMJ-IJ
Photo source: https://www.pexels.com/photo/photo-of-railway-on-mountain-near-houses-1658967/
Senior lecturer at the Zhejiang-Edinburgh Joint Institute (ZJE) and Edinburgh University.
Undergraduate Programme Director, Biomedical Informatics at ZJE.
I teach #imageanalysis & #dataanalysis with #RStats & #python. I study #heterogeneity in #pituitary (and other) cells.
I'm also very interested in #reproducibility and #openscience.
Joined Oct 2022
