

Nicola Romanò @nicolaromano@qoto.org
- Pronouns
- he/him
Senior lecturer at Edinburgh University and Zhejiang-Edinburgh Joint Institute (ZJE).
Undergraduate Programme Coordinator, Biomedical Informatics at ZJE.
I teach #imageanalysis & #dataanalysis with #RStats & #python.
My research is focused on how #heterogeneous behaviour in #pituitary (and other) cells shapes their function as a population.
I'm also very interested in #reproducibility and #openscience.
Joined Oct 2022
@failedLyndonLaRouchite @ethanwhite definitely not Hons projects...
Nicola Romanò
boosted

Nicola Romanò
boosted

There is people out there thinking that computational biologists spend less time on scientific projects (not true) and therefore deserve less credit or even no authorship in papers, compared to wet lab people.
They clearly have never seen all the years and work that takes to gain the knowledge to do it. Just like they clearly do not value such a knowledge on lab work, since they only care about how many hours someone spend doing something.
Just reading this very interesting paper on how many #replicates are needed for appropriate analysis of bulk #RNAseq data and comparing tools for DE gene expression.
#bioinformatics #article #goodread
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4878611/
From the abstract
With three biological replicates, nine of the 11 tools evaluated
found only 20%–40% of the significantly differentially expressed (SDE) genes identified with the full set of 42 clean replicates.
This rises to >85% for the subset of SDE genes changing in expression by more than fourfold. To achieve >85% for all SDE genes regardless of fold change requires more than 20 biological replicates.
@clathrin @richardsever Let me tell you a story about data reuse
I have a student who wants to re-analysing some sequencing data from a paper.
1. Paper reports the data will be shared on GEO at the time for publication. No GEO ID is present, although the paper has been published for a while now.
2. After digging onto GEO for longer than needed (it always feels like I'm back in the 90s on MySpace), I find the data. Well, part of it, the rest is nowhere to be found.
3. Several emails to the authors, no reply
4. In the meantime we manage to find the data. I confirm my hate for GEO.
5. Data is from human patients, which the paper indicates as patient 1,2,3 etc.
The patient numbers in the deposited data only partially match those in the paper. Luckily we're pretty confident we can tell who's who but still...
Data from one patient (out of 6) is missing
6. Out of three set of experiments, data is available only for two, the other are missing
The student has pretty much finished her project.
We're still waiting for the authors to reply to our emails.
I have to say, I've had much better experience with other papers, but still, I think we're a long way to have properly archived data.
@igutierrez@mastodon.social What do you edit PDF with though? Nowadays if I'm working with other people I use Google Docs. Formatting stays correct (not the case when going between Word/OpenOffice/LibreOffice esp with different OS), I can add comments and suggestions, have revision tracking, and can work synchronously with colleagues.
I'm not sure you can really do that with PDF, but I'll be super happy to be corrected.
@mcaleerp I guess you can also give feedback to colleagues to improve on assessments! Course assessment groups are a great place to do that
@mcaleerp I enjoy marking certain assessments, hate marking others.
It mostly depends on the assessment, there's a lot of badly designed ones around unfortunately.
Nicola Romanò
boosted

Big thanks to all who contributed to these initial guidelines, including the helpful reviewers and editors!
@gringene ooohhh I remember dismembering an old toy to get the motor out. Lots of fun! I was using it with Meccano rather than Lego though.
I also remember that at the time it sounded like the most interesting thing to do what's connecting the motor to the mains. I am sure your kids will be wiser, that didn't end well for the motor, although I had a nice pyrotechnics show in my room
Nicola Romanò
boosted

@nancylwayne @Frederik_Borgesius I think the main problem is not that there are people cheating. It's that universities don't do anything about them, and it's not just when they are 'big' scientists (well, they enabled them to become directors or what not)
Having seen a couple of cases of this, my impression is that the policy of many universities is to cover their assess and not do anything about 'problematic' employees, whether they falsify data, or harass others. It doesn't make sense, because I'd rather work for a uni that said 'we made a mistake hiring X, we will not support this person or their science anymore'. But apparently that's bad PR. 😭
Nicola Romanò
boosted

‘According to the Retraction Watch database, the 200 authors with the most retractions account for over a quarter of all 19,000 retractions. Many of the most prolific fraudsters are senior scientists at big universities or hospitals.’
https://web.archive.org/web/20230222193709/https://www.economist.com/science-and-technology/2023/02/22/there-is-a-worrying-amount-of-fraud-in-medical-research
#fraud #science #academia
Nicola Romanò
boosted

Check out our new commentary piece in @NatureEcoEvo - Better incentives are needed to reward academic software development rdcu.be/c6uMN software is critical for synthesizing & modeling big data in ecology and evolution … but current incentive structures are lacking
Nicola Romanò
boosted

Ok, so there is much discussion about the alt text on pictures. My mom is legally blind. As she has gotten older her sight is almost gone. She LIVES on the computer and to say she gets excited when special attention is paid for the blind is a great understatement. Please use alt text and describe the pictures you post. Describe it as if you had your eyes closed and the only link to the outside world is what a kind soul took an extra 5 minutes to type. Come on, do it, make someone’s day.#AltText
Nicola Romanò
boosted

If you see a bank account for donations to help cyclone victims, take the time to verify the account from an official published source.
For example: the recipient organisation's website.
Best not to just send money to an account repeated by social media users.
Nicola Romanò
boosted

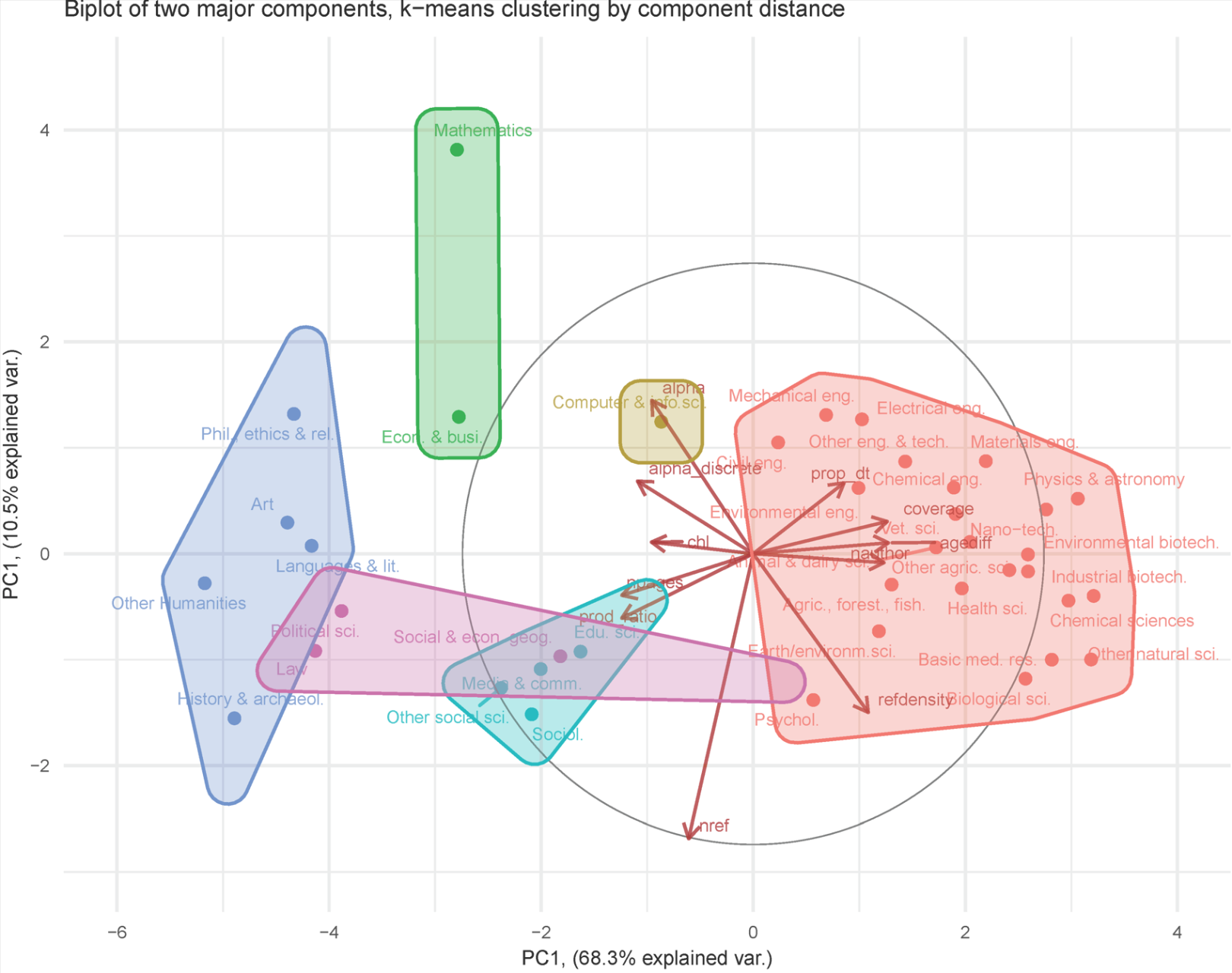
How are different scientific fields related, from a bibliometric point of view? Who writes longer papers? Uses more references? More recent references? In which fields does author position matter? Data for 20 years, all of Web of Science here:
https://doi.org/10.1162/qss_a_00246
Underlying, de-identified data can be found here: https://doi.org/10.5281/zenodo.7573523
Nicola Romanò
boosted

Okay, it's been a while since I last did this, and I haven't done it on mastodon yet, so I'm going to take a deep dive into p-values for another automated GWAS. Specifically, this one, relating to "Eosinophil percentage":
https://twitter.com/SbotGwa/status/1622218396661071874
I'm interested in this particular set of results because the p-values are impossibly large, with dozens of impossibly-large p-value peaks throughout the genome.
Also, the heritability of 0.22 is within the realm of possibility for finding true links.
Nicola Romanò
boosted

@ct_bergstrom Not sure what's this rant about. Nobody ever said decoder models are perfect or will have an actual understanding of the world. (Ok, maybe except for that one Google guy) OpenAI released a beta product which is incredibly helpful if used correctly but people like you just focus on its mistakes. It's like hating on cars because they can't take the stairs.
Nicola Romanò
boosted

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
@ct_bergstrom The LLM isn't bullshitting, because it's just a machine. It has no intentionality and no mind.
The engineers and execs at tech companies who are leveraging LLMs: they are bullshitting. It's an act of malice and should be treated as such.
- Pronouns
- he/him
Senior lecturer at Edinburgh University and Zhejiang-Edinburgh Joint Institute (ZJE).
Undergraduate Programme Coordinator, Biomedical Informatics at ZJE.
I teach #imageanalysis & #dataanalysis with #RStats & #python.
My research is focused on how #heterogeneous behaviour in #pituitary (and other) cells shapes their function as a population.
I'm also very interested in #reproducibility and #openscience.
Joined Oct 2022
