

Nicola Romanò @nicolaromano@qoto.org
- Pronouns
- he/him
Senior lecturer at Edinburgh University and Zhejiang-Edinburgh Joint Institute (ZJE).
Undergraduate Programme Coordinator, Biomedical Informatics at ZJE.
I teach #imageanalysis & #dataanalysis with #RStats & #python.
My research is focused on how #heterogeneous behaviour in #pituitary (and other) cells shapes their function as a population.
I'm also very interested in #reproducibility and #openscience.
Joined Oct 2022
Nicola Romanò
boosted

"Fun" is a kind of engagement. It is also subjective. Learning can be enjoyable; that's not identical to "fun".
Learning is better when not unpleasant, let alone miserable. But when you ask a person (of any age) to learn something, for no obviously good reason—other than to avoid punishment—they will find it unpleasant.
Curiosity is specific. Utility a bit more general. But neither work on kids who expect to be celebrities due to magical thinking.
Nicola Romanò
boosted

@ColinTheMathmo @rakhichawla I think that the "fun" stuff can be important for getting people over the initial activation barrier. I.e. those who say they're "just not good at maths" without ever seriously engaging with it. But I agree that fun is not enough in the long term.

@jasemrau @daniel Agree! Also "The novelty score is calculated using an algorithm that compares the combinations of keywords and cited journals in a scientific manuscript with those in previous publications and projects the types of paper that will be published in the future". This is really calling for people to game the system by using buzzwords and citing high impact-factor (not necessarily high impact!) papers. Just need to get a list of high-novelty keywords... :/
https://www.nature.com/articles/d41586-024-04021-w
What could go wrong really?
We should really start pushing #replication studies, not novelty for the sake of novelty. Also, I thought we were past #novelty = #impact ...
@ricci doesn't work for me (finds me but cannot retrieve posts) 🫤
Nicola Romanò
boosted

Nicola Romanò
boosted

That sounds misleading, an instance or server can have several moderators, you don't get to choose.
Maybe community, island,...
Nicola Romanò
boosted

Nicola Romanò
boosted

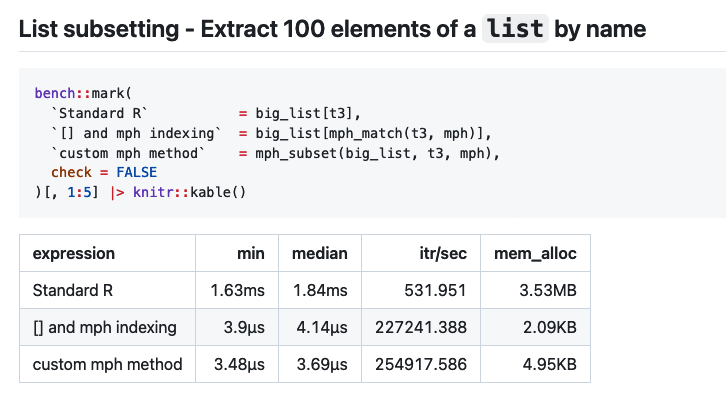
Introducing {oomph} an #RStats pkg technical demonstration of 500x faster named subsetting of vectors and lists
https://github.com/coolbutuseless/oomph
Given a static named list/vector, `oomph` subsets 100 elements from n=200k list 500x faster than R's standard method, & 1000x less memory allocation
Notes:
* Uses an order preserving minimal perfect hash
* Suited to static objects only - hashing object would need to be recalculated for every addition/removal
* A dynamic minimal perfect hash would be welcomed
Nicola Romanò
boosted

Hey are you a recent PhD with interests in #rstats and #psychology? Fancy joining the amazing stats teaching team in Psychology at Edinburgh University? Closing date for applications: 27 January https://edin.ac/3OVNTTE
We're looking for someone to take over a short term (1 year) #lectureship in #microbiology, #parasitology and #epidemiology, in programmes run jointly in China by the University of Edinburgh, Zhejiang University and the University of Edinburgh-Zhejiang University Joint Institute (ZJE).
The post is based in Edinburgh but the applicant will travel up to 12 weeks to ZJE to deliver teaching there.
For more information see
https://elxw.fa.em3.oraclecloud.com/hcmUI/CandidateExperience/en/sites/CX_1001/requisitions/preview/11695/?keyword=11695&mode=location
Nicola Romanò
boosted

BBC's Visual and Data Journalism Cookbook for R Graphics and their {bbplot} #RStats 📦are useful resources for making publication-quality graphics in
#R
Nicola Romanò
boosted

Hey, every fucking company these days, when you send me that email telling me that I have a new document to view, that I have to access by clicking on a link, then entering my credentials, then waiting for you to text me a code that I have to type in before having to hit through your terrible menu to find where you hid the messages... then looking again because that messages page wasn't the type of message the email was talking about...
Could you, I dunno... maybe mention what the fuck the document is fucking about in the god damned mother fucking email!!?!!??!
The new round of our fully funded 4 years PhD studentship is out!
This is the 3rd year of the Programme and it's an incredible opportunity to do your PhD in Edinburgh and improve your teaching skills by contributing to teaching at our joint Institute in Haining, China!
We have a variety of projects available, ranging from immunology to endocrinology, neurosciences, social research, and many more!
Nicola Romanò
boosted

Hello World :)
I am pleased to present you a small project that I have been working on these last weeks:
MARL (Mastodon Archive Reader Lite) is a small web app that allows you to explore in detail the content of your Mastodon posts archive, including attached files (images, videos, sounds), and with different search options.
🙏 Boosts welcome! 🙏
(More info in the post below 👇)
Nicola Romanò
boosted

The problem of fake science papers when trying to write a systematic review https://www.science.org/content/article/systematic-reviews-aim-extract-broad-conclusions-many-studies-are-peril
Nicola Romanò
boosted

#surveycomparison #representationbias
New #R-package out now!
"sampcompR" provides functions to easily compare surveys against benchmark surveys (e.g. for bias estimation) on a univariate, bivariate, and multivariate level.
By Björn Rohr & Barbara Felderer
https://bjoernrohr.github.io/sampcompR/
Confidence intervals and p-values can be either calculated with normal, parametric methods or as bootstrap confidence intervals and p-values and additionally adjusted for multiple testing.
Nicola Romanò
boosted

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
@tehstu I don't know how to get Microsoft to fix that, but I *do* know my solution to that whole fiasco last year... was to load Linux and never looking back since.
- Pronouns
- he/him
Senior lecturer at Edinburgh University and Zhejiang-Edinburgh Joint Institute (ZJE).
Undergraduate Programme Coordinator, Biomedical Informatics at ZJE.
I teach #imageanalysis & #dataanalysis with #RStats & #python.
My research is focused on how #heterogeneous behaviour in #pituitary (and other) cells shapes their function as a population.
I'm also very interested in #reproducibility and #openscience.
Joined Oct 2022
