

Nicola Romanò @nicolaromano@qoto.org
Senior lecturer at the Zhejiang-Edinburgh Joint Institute (ZJE) and Edinburgh University.
Undergraduate Programme Coordinator, Biomedical Informatics at ZJE.
I teach #imageanalysis & #dataanalysis with #RStats & #python. I study #heterogeneity in #pituitary (and other) cells.
I'm also very interested in #reproducibility and #openscience.
Joined Oct 2022
Nicola Romanò
boosted

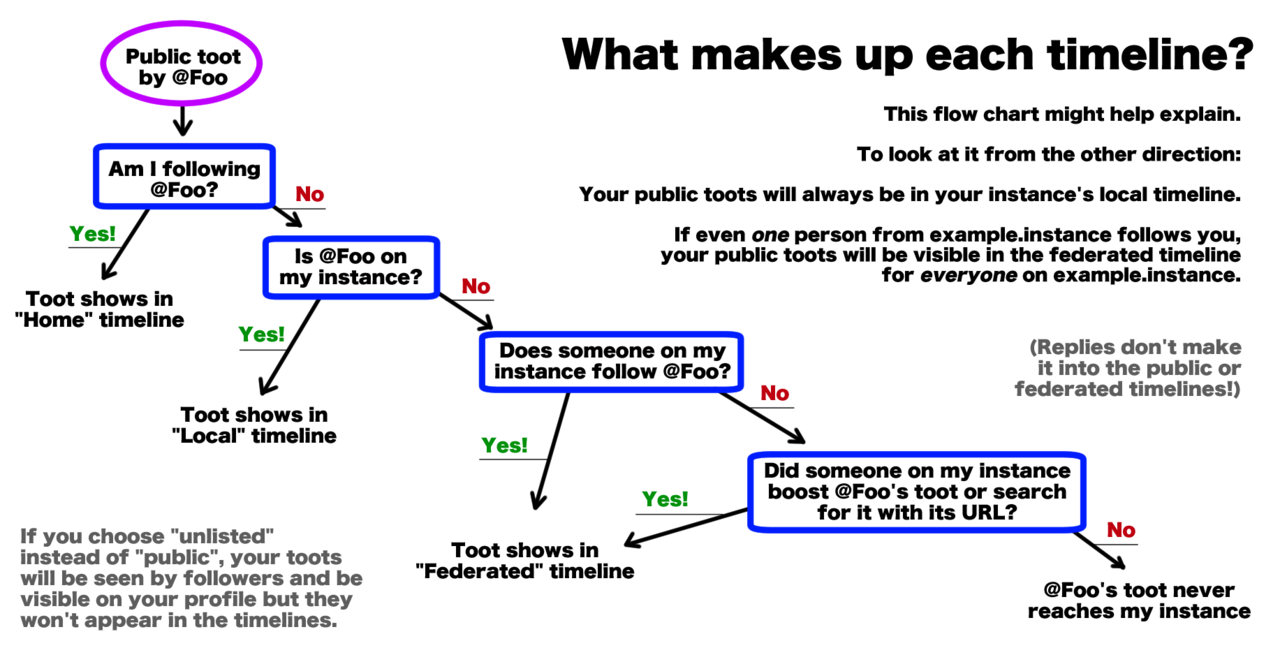
Just a reminder to all of those who are new around here and getting used to the mechanics of mastodon timelines.
( I didn't make this)
Nicola Romanò
boosted

@scullingmonkey
Many of the Cell press journals are on #mastodon too!
@CellReports
@CellMetabolism
@cellcellpress
@cellpress
@TrendsCellBio
@CellGenomics
@CellStemCell
@cellhostmicrobe
#science #CellPress #cellbiology #metabolism #stemcells
Nicola Romanò
boosted

Time for an #introduction
I'm a computational (bio)physicisct and have mostly worked with MD simulations of lipid membranes and membrane proteins but also some experience in machine learning and free energy calculations.
Currently I work as a senior scientist at Schrödinger in New York City, after doing a postdoc at Stanford University and a PhD at the Max Planck Institute of Biophysics.
Besides work, I'm an avid amateur photographer and I like reading about science, history, and languages.
Nicola Romanò
boosted

Should grants use a lottery approach? 🎟️
"Research shows that, barring a minority of outstanding projects, grant winners and losers are not decided by a precise and objective identification of worthy and unworthy projects. Instead, the luck of the draw — who reviews what proposal and the opinions they hold — generally determines these outcomes."
"It is excessively wasteful in terms of researchers’ time."
https://www.statnews.com/2022/10/21/research-funding-broken-lottery-approach-could-fix-it/
Nicola Romanò
boosted

Interesting webinar by Gabriella Rustici & Guillaume Desachy where they will share their experience about the @rstats ![]() journey AstraZeneca is currently on.
journey AstraZeneca is currently on.
R at AstraZeneca: upskilling our workforce through education, experience, and exposure
Nicola Romanò
boosted
Following up from the newly implemented #ungrading pedagogy (see https://lgatto.github.io/ungrading/), I have gathered an initial student feedback during this term's year committee, where student delegates and teaching staff meet to discuss how things have been so far.
Here's what concerns my 3rd bachelor course:
(1/3)
Nicola Romanò
boosted

I love all of you and I want nothing but the best for each of you, particularly those on infosec.exchange. I understand that Mastodon isn't Twitter, that DMs are end-to-end encrypted, that we are spread across different instances and it can be hard to find your friends, and that an instance can go away at any time, and that translating posts doesn't work correctly, and there is no native giphy support, and that some instances are overwhelmed and super slow, and that you don't think the federated model can scale to a billion users, or that it doesn't support full text search of every post and account, or that we can't comply with the GDPR, or that we don't support quote tweet style functionality, or that we shouldn't collect IP addresses, and many other things.
The fediverse is a work in progress. I've been here for going on 6 years. In that time, it's come a long, long way. That said, Mastodon is not going to appeal to everyone. The decisions I make are not going to appeal to everyone. No one is forcing you to be here. No one is forcing you to disclose your personal secrets into a network of federated servers running by volunteers and hobbyists. NB: this is not Twitter. It has some similar functionality, but it is not Twitter. Parts of it are better, IMO, and parts are not. The security community is generally among the most skilled and competent IT people the world has to offer. Mastodon is open source. Do you see where I'm going?
I set this instance up a long time ago for reasons I don't even remember. I have poured my soul into this thing because I believe in the importance of this community. I have effectively peaked in my career as a CISO and I and my family live well. I am not running this instance for fame, money, a better job, or anything other than wanting to foster a community of people that can learn from each other and make the world a better place. That's it.
As I've said in several recent interviews, I felt particularly obligated to ensure the security community had a good handing spot in the fediverse as everyone was running for the doors in Twitter. We've grown from 180 active users to about 30000 in the span of 3 weeks. I do not expect everyone to stay. Some will set up their own instances. Some will move to one of the other excellent security focused instances. Some will give up and move to on to some other social media. And that is OK. While I am super excited to see the buzz here, I don't have subscriber targets, engagement targets, retention targets, or anything else. The only metric I hold myself to is whether I think this is serving a useful purpose to the community.
I appreciate all of you, regardless of where you land. Infosec.exchange has been here for a long time and will continue to be here for you.
Nicola Romanò
boosted

Just migrated to mastodon from Twitter and looking for researchers to follow here to get started. I found some nice lists separated by field but haven't found any for natural language processing. Does anyone know of one?
Nicola Romanò
boosted

Also, if you build Shiny apps, you might want to consider submitting a proposal to be a speaker at ShinyConf2023 (@ShinyConf)
More details here: shinyconf.appsilon.com/become-a-speaker
Nicola Romanò
boosted

Digital publications without a print issue - "it will never work".
Open Access - "it will never work".
#Preprints - "it will never work"-
Open peer review - "it will never work".
#OpenData - "it will never work."
If I would write it today, I'd add:
Open source social infrastructure, hosted by academics. - "It will never work."
Nicola Romanò
boosted

Love, love, love to see the old "remote work is ineffective" argument being made after having just lived through two years of remote work. 🤪
How about you just say the truth? "I don't trust you and can't monitor you unless you're in the office."
Nicola Romanò
boosted

#️⃣ This video helped me add a column to Mastodon that contains various hashtags I want to follow.
⚙️ First you have to go to your preferences and enable advanced web interface.
Nicola Romanò
boosted

@nicolaromano apologies if this is already on your radar, but as someone outside the field I appreciated the clarity and detail in this paper https://elifesciences.org/articles/66747
I am wondering if anyone has experience in doing comparative analysis of #scRNAseq datasets from different species, or if anyone knows of good resources about that esp with an #evolutionaryBiology focus?
I'd like to point out this great little table about reproducible research.
This is from a great resource "The Turing Way handbook to reproducible, ethical and collaborative data science", which you can find here: https://the-turing-way.netlify.app/welcome.html
Nicola Romanò
boosted

@nicolaromano @datamaps @arnaudlerouzic @smach @MichaelIngrisch @rstats Plus you can easily write "base R" code that will break without the right system dependencies, that relies on a specific file structure, will only work on one OS, etc.. None of which CRAN is going to help you with. And personally I see those kind of problems in analysis scripts far more often than broken dependencies.
Nicola Romanò
boosted

Probably one of the most simple & interesting (for its utterly basic qualities) #cellularAutomata I've ever written...
Probabilistic (1% mutation chance per frame)
Lower mutation threshold (non-probabilistic)
Nicola Romanò
boosted

@arinbasu1 @nicolaromano @rstats It is true that using base R has a higher likelihood of reproducibility in the near term than the tidyverse suite. However, there is still a chance that a change in R causes breaking changes (e.g. R 4.0 with the `stringsAsFactors` default switch). What Nicola's point is that it's better to avoid that situation altogether with renv, which generates a lockfile and restores pkg versions using MRAN, taking care of random breaking changes
Nicola Romanò
boosted

@arnaudlerouzic @datamaps @MichaelIngrisch @rstats Why? Because syntax preference is a highly personal thing. "Intuitive" and "human-readable" are subjective. Many people enjoy the dplyr approach to data wrangling, and it's made #rstats more accessible to a lot of people who don't come from a traditional coding background. I really like dplyr. I also really like data.table (but IMO it has a steeper learning curve for people without coding experience. I probably wouldn't teach it in a newsroom.)
Nicola Romanò
boosted

{kind=link}
{kind=link}
{kind=link}
@arnaudlerouzic @datamaps @smach @rstats
So what would you recommend then to teach beginners data visualization in R? I have yet to see the convincing one-liner base-R plot that is equivalent to what a freshly converted excel-user can produce with ggplot
Senior lecturer at the Zhejiang-Edinburgh Joint Institute (ZJE) and Edinburgh University.
Undergraduate Programme Coordinator, Biomedical Informatics at ZJE.
I teach #imageanalysis & #dataanalysis with #RStats & #python. I study #heterogeneity in #pituitary (and other) cells.
I'm also very interested in #reproducibility and #openscience.
Joined Oct 2022
