

Nicola Romanò @nicolaromano@qoto.org
- Pronouns
- he/him
Senior lecturer at Edinburgh University and Zhejiang-Edinburgh Joint Institute (ZJE).
Undergraduate Programme Coordinator, Biomedical Informatics at ZJE.
I teach #imageanalysis & #dataanalysis with #RStats & #python.
My research is focused on how #heterogeneous behaviour in #pituitary (and other) cells shapes their function as a population.
I'm also very interested in #reproducibility and #openscience.
Joined Oct 2022
Nicola Romanò
boosted

Underlying problem is that we literally have college courses in noise mining (we call them Stats 101) so millions of scientists are out there noise mining, and so we have a lot of papers that really do have low evidentiary value. It's not because they're not preregistered, it's because the people doing the analysis wouldn't know what a good analysis looked like, and in fact would likely fight a good analysis tooth and nail.
Nicola Romanò
boosted

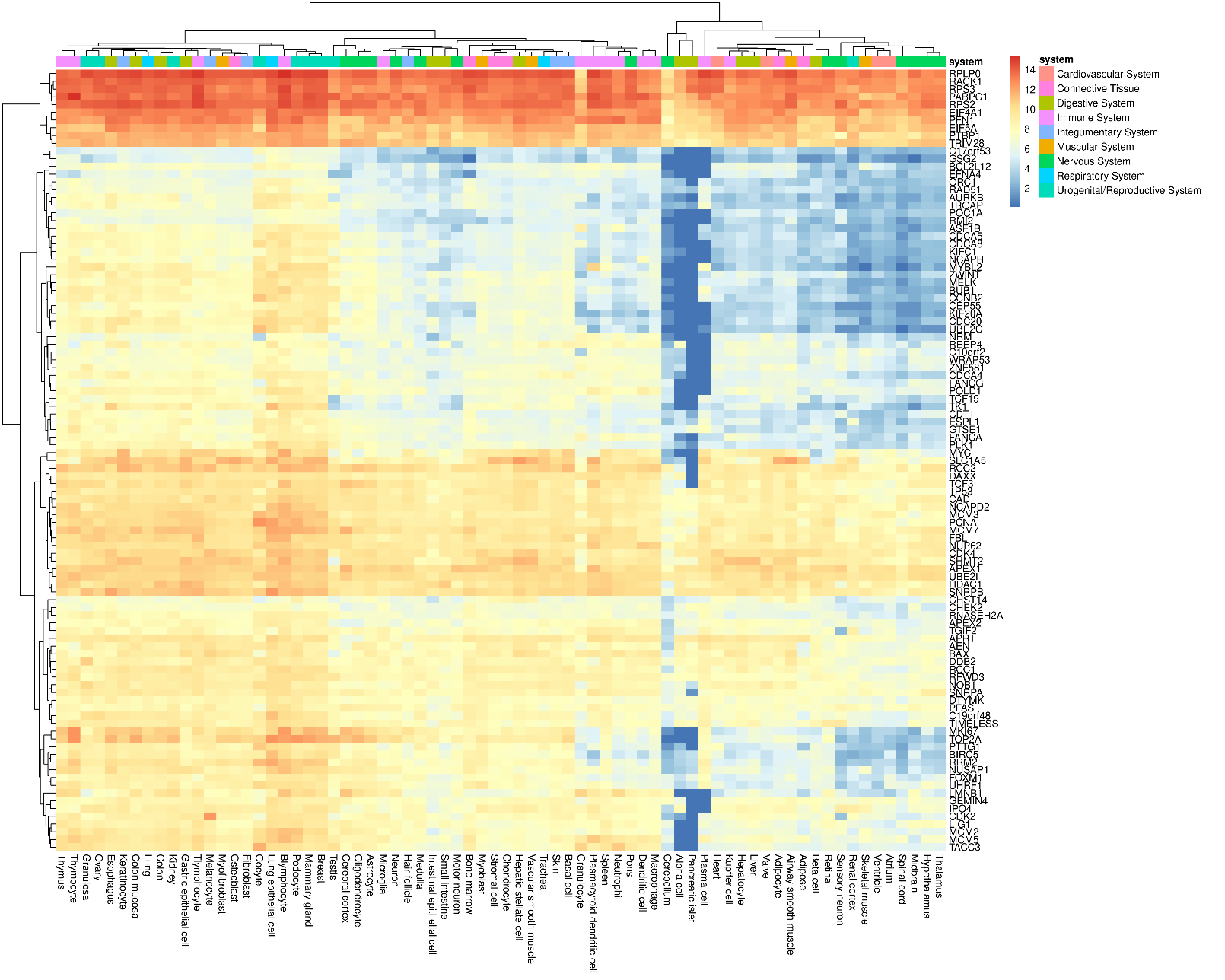
I wrote a script that takes as input a gene of interest:
```console
./script/plot_heatmap.sh -p 10 TP53
```
and generates a gene expression heatmap with genes that have correlated expression patterns.
Behind the scenes is a Bash script (calling `gget`) and a #Rstats script available at https://github.com/davetang/archs4_heatmap
@marilenharo @nature @tatsuya_amano and then there's always the dumb reviewer that complains a priori about the quality of English, just because they see a non-English sounding name...
Nicola Romanò
boosted

Scientists whose first language is not English spend much longer to read and write papers in English and prepare for international conferences. @tatsuya_amano and colleagues worked to measure this invisible struggle. I wrote about their work for @nature https://www.nature.com/articles/d41586-023-02320-2
@devezer I always tell students that reading papers (e.g. for a journal club) is about critiquing, not criticizing.
That is not to say one should ignore the negatives, but you should be looking at those with a positive attitude. How could this have been improved? Was it possible to do it? Does it really affect the conclusions of the article?
Nicola Romanò
boosted

One of my professors during PhD used to say “you can drive a truck through the holes in any given paper. so you look for what you *can* learn instead.” and being the smartass grad students we used to think driving that truck was fun. After so many years, I now appreciate her wisdom more than ever. All scholarly work has limitations but it’s refreshing when people critically evaluate what’s the actual value of the research. It's about humility, honesty, rigorous intellectual work.
Very happy to share our newly published #article "Sex differences in pituitary corticotroph excitability".
It is well known that sex differences exist in stress-related disorders, with women having twice the lifetime rate of depression compared to men and most anxiety disorders.
Corticotroph cells in the pituitary gland are a key player in the generation of hormonal stress responses. However, their contribution to sexually differential responses of the stress axis (which might underlie differences in stress-related disorders) is very poorly understood.
We found sex differences in the electrical activity of these cells, which could be related to differences in their gene expression pattern.
These findings shed light on the cellular mechanisms underlying sex differences in stress responses, contributing to a better understanding of stress-related disorders and potential avenues for diagnosis and treatment.
#stress #pituitary #research #electrophysiology #physiology #corticotrophs #hpa #anxiety
https://www.frontiersin.org/articles/10.3389/fphys.2023.1205162/full
Nicola Romanò
boosted

New posting! This addresses the recent controversy at the 2023 Lindau Nobel Laureate meeting, where one of the speakers used his time to complain that he felt discriminated against as a white man.
To my mind, that isn't what's surprising and shocking about the episode.
The surprising thing is that on this occasion, a courageous young female scientist actually called him out on it.
The shocking thing is that despite such sexist, chauvinistic comments still being commonplace, such interventions basically never happen. And they should. #womeninstem
Nicola Romanò
boosted

Many prominent anti-vaccine influencers claim biomedical credentials. In a new pre-print, we quantify the size & influence of the group of perceived experts in the anti-vaccine community on Twitter.
https://www.medrxiv.org/content/10.1101/2023.07.12.23292568v1.full.pdf+html
Nicola Romanò
boosted

Bad values dont me new values... A good person encouraging education to children is just as good a person regardless if they wear pants or a dress... THAT is a good value to teach kids.
@admitsWrongIfProven @iDoobyLeaves@noagendasocial.com
Nicola Romanò
boosted

Microsoft "confirmed Tuesday that its validation procedure had been manipulated to digitally sign dozens of pieces of software."
Microsoft, Adobe, these firms have autoupdaters, installed on so many of our machines, that will run without question code signed by the mothership.
That's bad enough. How much should you trust Microsoft, both its intentions and internal security?
It's absolutely terrifying that hostile third parties have managed it. https://www.washingtonpost.com/national-security/2023/07/12/microsoft-hack-china/
ht @GossiTheDog
Nicola Romanò
boosted

reanalyzerGSE: tackling the everlasting lack of reproducibility and reanalyses in transcriptomics https://www.biorxiv.org/content/10.1101/2023.07.12.548663v1?med=mas
Nicola Romanò
boosted

Really not enjoying this “will they won’t they”. UK science is at stake. Sunak and von der Leyen fail to agree Horizon Europe deal.
https://www.researchprofessionalnews.com/rr-news-uk-politics-2023-7-sunak-and-von-der-leyen-fail-to-agree-horizon-europe-deal/
Nicola Romanò
boosted

Just came across this very interesting #preprint about #bias in #GPT detectors (surprise, surprise...).
Weixin Liang et al. - GPT detectors are biased against non-native English writers - 2023
https://arxiv.org/abs/2304.02819
"Our results call for a broader conversation about the ethical implications of deploying ChatGPT content detectors and caution against their use in evaluative or educational settings, particularly when they may inadvertently penalize or exclude non-native English speakers from the global discourse."
Nicola Romanò
boosted

Please boost/forward/tape to lab fridge etc.
Are you currently working on a #scientificwriting project such as a manuscript, grant proposal, job application, or research/teaching statement? Struggle to find place/time to write? Interested in learning how to improve the clarity and effectiveness of your professional writing? If so, consider applying to the CSHL Scientific Writing Retreat!
DM me with any questions. See interview with us here:
https://currentexchange.cshl.edu/blog/2021/8/a-word-from-32
https://meetings.cshl.edu/courses.aspx?course=C-WRITE&year=23
Nicola Romanò
boosted
Enjoyed reading "Using prototyping to choose a #bioinformatics workflow management system". Paper describes authors' 10 day experience searching and implementing a workflow. Summary: Need to decide which tool to use? Shortlist a list of potentially useful tools based on your needs. Start using each tool on a simpler problem. Assess the suitability of each tool. Paper contains useful tips for building reproducible workflows and links to many useful resources. https://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1008622
@GatekeepKen @donniecash818 Don't think a supposedly private conversation about something that must have been devastating can be classified as bragging...
Nicola Romanò
boosted

Read an article today about why Americans think alcohol has health benefits and it's apparently another "well the French are healthy and they do X so it's healthy to do X."
So here's your periodic reminder that France (and Italy, and Sweden, and Japan, and basically every country you've seen in a "this country is so healthy, what's their secret?" headline) has universal health care.
The secret is access to health care. It's always access to health care.
Nicola Romanò
boosted

{kind=link}
{kind=link}
{kind=link}
- Pronouns
- he/him
Senior lecturer at Edinburgh University and Zhejiang-Edinburgh Joint Institute (ZJE).
Undergraduate Programme Coordinator, Biomedical Informatics at ZJE.
I teach #imageanalysis & #dataanalysis with #RStats & #python.
My research is focused on how #heterogeneous behaviour in #pituitary (and other) cells shapes their function as a population.
I'm also very interested in #reproducibility and #openscience.
Joined Oct 2022
